Picture this: you’re building an AI feature for your product—maybe a customer-support assistant, a “search across our docs” chatbot, or an internal knowledge tool for employees. You try a few models, but the results feel random, the answers aren’t grounded in your data, and production reliability becomes a real headache.
That’s the problem Cohere solves.
Cohere is an enterprise-focused AI platform that offers language models (like the Command family) plus “retrieval” tools (Embeddings + Rerank) so businesses can build practical AI applications such as chat assistants, semantic search, and RAG (retrieval augmented generation) experiences.
One reason teams like Cohere is that it’s designed for real production workflows: you can ground responses on external documents (RAG) and even generate citations when using the right setup, which helps reduce hallucinations in business scenarios.
And yes—this is a real “pay for usage” platform. Cohere publishes pricing pages that show token-based costs for its generative models (with different rates for input vs output), and separate pricing logic for embeddings and reranking.
By the end of this guide, you’ll understand what Cohere is, how it works step by step, what features make it successful, how the business model works, and what it takes to build a Cohere-like AI platform for your niche—plus how Miracuves can help you launch faster with proven AI-platform building blocks.
What Is Cohere? The Simple Explanation
Cohere is an enterprise-focused AI platform that gives businesses ready-to-use AI building blocks—mainly generative language models (for chat and content) plus retrieval tools like Embeddings (to turn text into “meaning vectors”) and Rerank (to sort search results by relevance). Together, these help companies build practical features like internal knowledge assistants, customer support copilots, semantic search, and RAG apps.
The core problem Cohere solves
Most companies want AI, but they run into the same issues:
- Their data is scattered across docs, PDFs, wikis, tickets, emails
- Chatbots answer confidently but can “hallucinate” without grounding
- Search results are messy and not truly relevant
- Production reliability, privacy, and security matter more than “fun” chat
Cohere’s approach is: don’t only generate text—ground it in your data using retrieval (Embeddings + Rerank) and RAG workflows.
Target users and common use cases
Cohere is typically used by:
- Enterprises and regulated industries (finance, healthcare, government, etc.)
- Product teams adding secure AI to apps
- Data/ML teams building search + assistant experiences
Common use cases:
- “Chat with our policies/SOPs” internal assistants (RAG)
- Semantic search using embeddings (better than keyword-only search)
- Reranking search results so the best answers appear at the top
- Enterprise chat and automation use cases (secure and customizable AI)
Current market position with stats
Cohere is widely positioned as a security-first enterprise AI company focused on business deployments rather than consumer chat apps.
Public reporting also highlights that Cohere’s enterprise focus drove strong revenue growth and long-term contracts in regulated industries.
Why it became successful
- Clear enterprise positioning: privacy/security + customization over “viral chatbot” behavior
- Strong retrieval stack: embeddings + rerank + RAG citations = more trustworthy answers for business workflows
- Production-ready model pricing and deployment options designed for real applications
How Does Cohere Work? Step-by-Step Breakdown
For users (developers, product teams, enterprises)
1) You pick the building block you need
Cohere is usually used in three “building block” ways:
- Generate text (chat, drafting, summarization) using the Command family of models
- Create embeddings (turn text into searchable “meaning vectors”) for semantic search and RAG retrieval
- Rerank results (reorder search matches so the best ones rise to the top)
Most production apps combine all three.
2) You send a request through the API (or platform tools)
Your app sends:
- an instruction (what you want)
- optional context documents (what the AI should rely on)
- constraints like style, length, or format
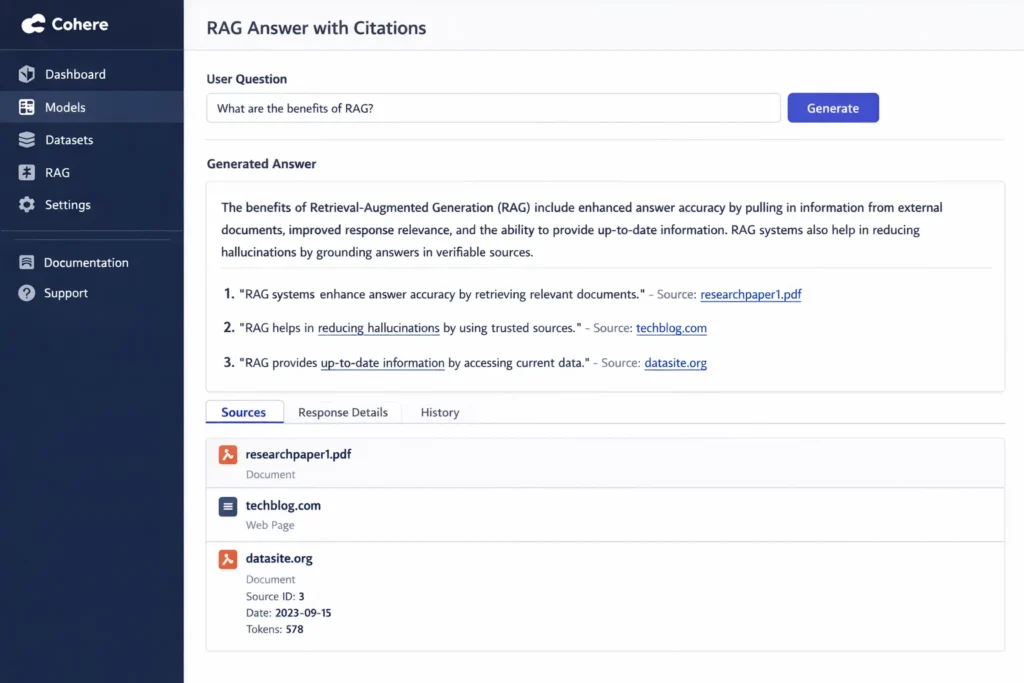
Cohere’s docs show end-to-end RAG flows that connect chat + embed + rerank so answers are grounded in documents.
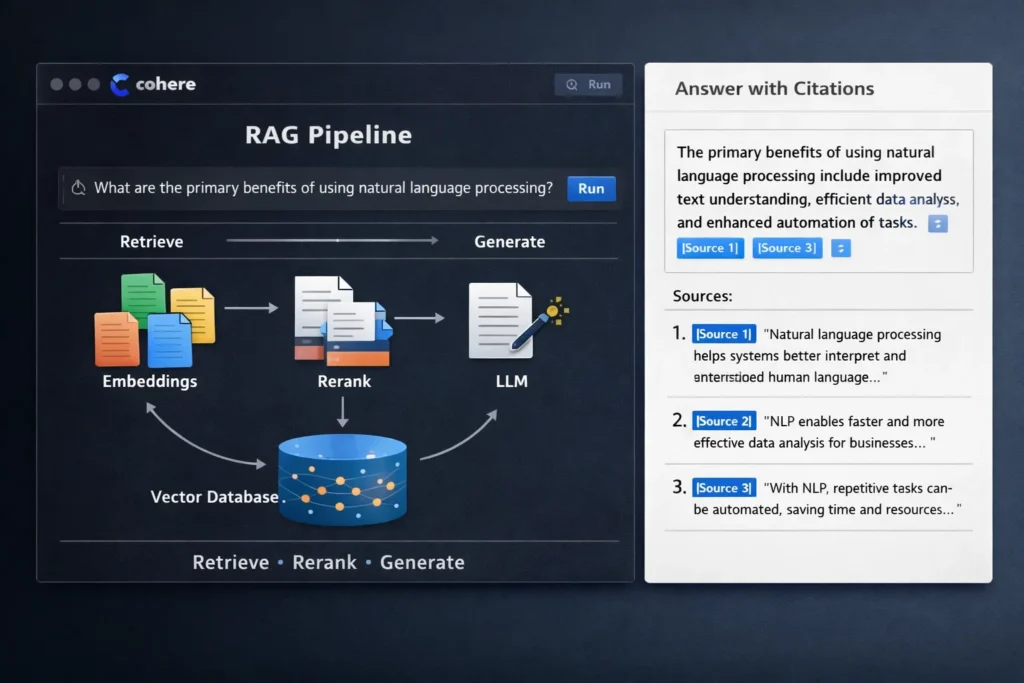
3) If you’re building RAG, you follow a simple pipeline
Here’s the classic Cohere-style RAG workflow:
- Convert your documents into embeddings (so they can be retrieved by meaning)
- When a user asks a question, embed the question too
- Retrieve the most relevant document chunks from your vector store
- Rerank those chunks using Cohere’s Rerank endpoint to improve relevance
- Send the top reranked chunks into the chat/generation model so it answers using that context
- Return an answer, often with citations that point back to the source text (so users can verify)
Typical user journey (example)
Let’s say you’re building “Ask our HR Policy” inside a company portal:
- Employee asks: “How many days of sick leave do I get?”
- Your system retrieves policy sections via embeddings
- Rerank boosts the exact policy clause above loosely related pages
- Cohere generates a final answer and attaches citations to the policy lines it used
That’s how you reduce hallucinations: the model isn’t guessing, it’s responding from your documents.
For service providers (platform owners using Cohere inside their product)
Onboarding process
If you’re the “service provider” (you’re building the app), your onboarding usually looks like:
- Create a Cohere account and API keys
- Choose models for each job (chat/generation vs embeddings vs rerank)
- Set safety, logging, and usage limits on your side
- Connect your knowledge sources (docs, PDFs, support tickets, KB articles)
How you operate the platform
You typically run Cohere in a controlled pipeline:
- Embed and store data (one-time and ongoing updates)
- Rerank during searches (every query)
- Generate responses only after retrieval (so answers stay grounded)
Earnings / pricing structure
Cohere’s pricing is usage-based, but it differs by feature type:
- Generative models are priced by tokens (input and output priced differently)
- Embedding models are priced by tokens embedded
- Rerank models are priced by the number of searches
Technical overview (simple, no jargon)
Think of Cohere like this:
- Command models write the answer
- Embed helps your app find the right information by meaning
- Rerank helps you choose the best pieces of information before answering
- Citations help your users trust the answer because they can see what source text it came from
Read More :- How to Develop an AI Chatbot Platform
Cohere’s Business Model Explained
How Cohere makes money (all revenue streams)
Cohere is a B2B AI platform, so its revenue is mainly from two buckets:
- API usage for models (generative + retrieval) on usage-based pricing
- Enterprise contracts for secure, private, and customizable deployments (often long-term deals with regulated industries)
Pricing structure with current rates
Cohere publishes model pricing that typically separates input tokens and output tokens for generative models, and uses different units for retrieval tools:
- Generative (Command family): priced per token; input and output priced differently
- Embeddings: priced by number of tokens embedded
- Rerank: priced by quantity of searches
Example prices shown on Cohere’s pricing page include token-based rates for models like Command and Command R / R+ variants (with distinct input vs output rates).
Commission/Fee breakdown (what you’re really paying for)
Cohere isn’t a marketplace, so there’s no “commission.” Instead, costs usually come from:
- Tokens used (for generative models)
- Embedding volume (tokens embedded)
- Rerank volume (number of rerank searches)
- Deployment style (enterprise/private deployments can be contract-based depending on requirements)
Market size and growth stats (signals that money is flowing here)
Cohere’s enterprise focus has translated into meaningful revenue scale. Reuters reported Cohere reached about $100M annualized revenue (as of May 2025), driven largely by demand for secure, customizable deployments in regulated industries.
Reuters also later reported a $6.8B valuation after a funding round, again emphasizing its enterprise positioning and “North” product direction.
Profit margins insights (how an API business becomes profitable)
For AI API platforms, margins typically improve when:
- Customers sign long-term enterprise contracts (predictable volume)
- More usage shifts into retrieval-first pipelines (embed + rerank + grounded generation reduces wasted tokens)
- Customers optimize prompts, context size, and reranking depth (lower usage per task)
Revenue model breakdown
| Revenue stream | What it includes | Who pays | How it scales |
|---|---|---|---|
| Token-based generative usage | Command family usage billed by input/output tokens | Builders + companies | Grows with chat + automation volume |
| Embeddings usage | Turning docs/queries into vectors for retrieval | Teams building search/RAG | Grows with document volume + query traffic |
| Rerank usage | Sorting retrieved chunks by relevance per query | Search/RAG teams | Scales with search requests |
| Enterprise deployments | Private, secure, customizable deployments + support | Regulated enterprises | Larger contracts, longer retention |
Key Features That Make Cohere Successful
1) Command models for enterprise-grade generation
Why it matters: Businesses need consistent, controllable outputs for real workflows (support, docs, analysis), not random “chatty” responses.
How it benefits users: You can build assistants, summarizers, and automation features that feel stable and professional.
Technical innovation involved: Cohere provides model families (like Command variants) optimized for production use through a clean API.
2) Embeddings for semantic search and RAG
Why it matters: Keyword search misses meaning—especially in internal docs, policies, and support knowledge bases.
How it benefits users: Users can search and retrieve the right content even if they don’t use the exact keywords.
Technical innovation involved: Embedding models convert text into vectors so retrieval works by “meaning similarity,” enabling semantic search and RAG pipelines.
3) Rerank for “best results first” retrieval
Why it matters: Retrieval often returns “kind of related” results; the best answer may be buried.
How it benefits users: Better relevance = better grounded answers and fewer hallucinations in RAG apps.
Technical innovation involved: Rerank models score and reorder retrieved passages to push the most relevant evidence to the top.
4) RAG guidance designed for real deployments
Why it matters: Most companies don’t want a “demo chatbot”—they want an assistant that answers using company documents.
How it benefits users: Clear patterns help teams implement RAG faster and avoid common mistakes (bad chunking, weak retrieval, missing citations).
Technical innovation involved: Cohere documentation provides end-to-end RAG examples that combine embeddings + rerank + generation.
5) Citations support for trust and verification
Why it matters: In enterprise settings, “trust me” answers don’t work—teams need proof.
How it benefits users: Users can verify where an answer came from, making AI usable for policies, compliance, and internal knowledge.
Technical innovation involved: Citation-style outputs connect generated answers back to source chunks used in retrieval context.
6) “Retrieval-first” design to reduce hallucinations
Why it matters: Pure generation can confidently invent details—especially when questions involve company-specific info.
How it benefits users: More accurate answers because the model is constrained by retrieved evidence.
Technical innovation involved: The product stack encourages embedding + rerank + grounded generation flows instead of raw prompting.
7) Clear, unit-based pricing across components
Why it matters: AI costs can spiral if pricing is unclear.
How it benefits users: Teams can forecast costs separately for generation, embeddings, and reranking—and optimize the most expensive part.
Technical innovation involved: Pricing is split by workload type (tokens for generation/embeddings; per-search style pricing for rerank).
8) Enterprise positioning (security + regulated industries focus)
Why it matters: Many companies can’t use consumer-style AI tools due to governance and compliance constraints.
How it benefits users: Easier adoption in regulated environments where security, privacy, and policy controls matter.
Technical innovation involved: Cohere’s product direction and business strategy emphasize enterprise readiness and deployment flexibility.
9) Search + assistant building blocks that fit together
Why it matters: Teams hate glue-work between multiple vendors for embeddings, ranking, generation, and citations.
How it benefits users: Faster time-to-production because the components are designed to connect as one pipeline.
Technical innovation involved: API-first modular stack (generate + embed + rerank + RAG patterns) built to be composed.
10) Strong traction signals from enterprise revenue growth
Why it matters: In B2B AI, traction often comes from repeatable deployments and long-term contracts.
How it benefits users: More confidence the platform is built for production and long-term support.
Technical innovation involved: Cohere’s momentum is tied to enterprise adoption and product focus (reported revenue/valuation signals).
The Technology Behind Cohere
Tech stack overview (simplified)
Cohere is best understood as three connected layers you combine depending on what you’re building:
- Generate layer (Command models) for chat, writing, summarizing, and reasoning-style tasks
- Retrieval layer (Embeddings) to find the right information from your documents by meaning
- Ranking layer (Rerank) to sort retrieved results so the most relevant evidence is used first
Together, these layers help teams build “enterprise-safe” assistants that answer based on real sources rather than guessing.
Real-time features explained (how Cohere fits into live products)
Most Cohere-powered apps run in a real-time loop like this:
- User asks a question in your app
- Your backend retrieves relevant internal content (via embeddings + your vector database)
- Rerank refines the shortlist to the best few passages
- The generation model creates a final answer from those passages (often with citations)
- Your app displays the response instantly in chat, search, or workflow UI
This design keeps answers responsive while staying grounded in your data.
Data handling and privacy (what happens to your information)
In a typical Cohere integration, you control:
- What text you send (redact or minimize sensitive data)
- Where your documents live (your storage, your vector DB)
- Access control (who can query what)
- Logging and retention policies inside your product
Cohere’s docs focus heavily on practical enterprise patterns like RAG and citations because business users need traceability and verification.
Scalability approach (how Cohere apps scale)
Cohere apps scale well when you design for:
- Efficient chunking and indexing (so retrieval stays fast)
- Limiting context size (only send top reranked chunks into generation)
- Caching embeddings for repeated queries and documents
- Separating workloads (embedding pipelines vs real-time chat requests)
This is also how teams control cost—because token usage is one of the biggest pricing drivers in AI apps.
How mobile apps and web apps typically use Cohere
Most production implementations follow this pattern:
- Web/mobile frontend collects user input
- Secure backend calls Cohere APIs (so keys never sit inside the app)
- Backend connects to your data sources (docs, KB, tickets, CRM)
- Backend returns a final answer (plus citations or sources) to the frontend
API integrations (where Cohere becomes powerful)
Cohere becomes much more valuable when connected to real business systems, such as:
- Knowledge bases and internal wikis (policies, SOPs)
- Support platforms (tickets, macros, help center articles)
- Product documentation repositories
- CRM notes and sales enablement docs
In practice, the “integration” is mostly your retrieval pipeline: embedding + storing + retrieving + reranking before generation.
Why this tech matters for business
The main win is reliability. Cohere’s stack pushes teams toward a grounded workflow:
- Retrieve the right evidence
- Rerank it so quality stays high
- Generate an answer that stays aligned with sources (often with citations)
That’s exactly what businesses need to make AI usable for real operations—support, internal knowledge, and decision-making—without “AI guessing.”
Building Your Own Cohere-Like Platform
Why businesses want Cohere-style AI platforms
Cohere’s success highlights what companies actually want from AI: usable outcomes inside real workflows, not just “AI chat.” Businesses want Cohere-like platforms because they can:
- Build assistants grounded in internal documents (policies, SOPs, help centers)
- Improve search relevance and reduce time wasted hunting for information
- Reduce support workload with accurate, traceable answers
- Add AI automation (summaries, classification, routing) without losing control
- Deploy AI in regulated environments where privacy, governance, and safety matter
Key considerations for development
To build a Cohere-style product (enterprise AI + retrieval stack), your platform needs:
- Generative model layer (chat, summarize, draft, classify)
- Embeddings for semantic retrieval (documents + queries)
- Reranking to improve relevance before generation
- RAG workflows (chunking, vector store, retrieval logic, evaluation)
- Citations and traceability (source mapping)
- Admin controls (roles, permissions, audit logs, usage caps)
- Monitoring (quality, latency, cost, hallucination rate)
Read Also :- How to Market an AI Chatbot Platform Successfully After Launch
Cost Factors & Pricing Breakdown
Hugging Face–Like App Development — Market Price
| Development Level | Inclusions | Estimated Market Price (USD) |
|---|---|---|
| 1. Basic AI Model Hosting & API MVP | Core web platform for hosting and calling ML/AI models, user registration & login, basic model upload or API connection, simple inference endpoints, basic documentation portal, API key management, minimal moderation & safety filters, standard admin panel, basic usage analytics | $100,000 |
| 2. Mid-Level AI Model Platform & Developer Hub | Multi-model hosting support, model versioning, dataset storage basics, inference API endpoints (text/image/audio), usage dashboards, workspace/projects, access control, SDK samples, stronger moderation hooks, credits/usage tracking, analytics dashboard, polished web UI and developer console | $200,000 |
| 3. Advanced Hugging Face–Level AI Platform Ecosystem | Large-scale multi-tenant ML platform with model hub, dataset hub, fine-tuning pipelines, enterprise orgs & RBAC/SSO, model marketplace, inference scaling infrastructure, API gateway, audit logs, advanced observability, cloud-native scalable architecture, robust safety & policy enforcement | $350,000+ |
Hugging Face–Style AI Model Platform Development
The prices above reflect the global market cost of developing a Hugging Face–like AI model hosting, sharing, and inference platform — typically ranging from $100,000 to over $350,000+, with a delivery timeline of around 4–12 months for a full, from-scratch build. This usually includes model hosting infrastructure, dataset management, inference APIs, developer tooling, analytics, governance controls, and production-grade cloud infrastructure capable of handling high compute workloads.
Miracuves Pricing for a Hugging Face–Like Custom Platform
Miracuves Price: Starts at $15,999
This is positioned for a feature-rich, JS-based Hugging Face-style AI platform that can include:
- AI model hosting or external model API integrations
- Model inference APIs for text, image, or audio use cases
- Developer portal with API documentation and usage dashboards
- User accounts, projects/workspaces, and access controls
- Usage and credit tracking with optional subscription or pay-per-use billing
- Core moderation, compliance, and safety hooks
- A modern, responsive web interface plus optional companion mobile apps
From this foundation, the platform can be extended into model marketplaces, dataset hosting, fine-tuning workflows, enterprise AI governance, and large-scale AI SaaS deployments as your AI ecosystem matures.
Note: This includes full non-encrypted source code (complete ownership), complete deployment support, backend & API setup, admin panel configuration, and assistance with publishing on the Google Play Store and Apple App Store—ensuring you receive a fully operational AI platform ecosystem ready for launch and future expansion.
Delivery Timeline for a Hugging Face–Like Platform with Miracuves
For a Hugging Face-style, JS-based custom build, the typical delivery timeline with Miracuves is 30–90 days, depending on:
- Depth of AI model hosting and inference features
- Number and complexity of model, storage, billing, and moderation integrations
- Complexity of enterprise features (RBAC, SSO, governance, audit logs)
- Scope of web portal, mobile apps, branding, and long-term scalability targets
Tech Stack
We preferably will be using JavaScript for building the entire solution (Node.js / Nest.js / Next.js for the web backend + frontend) and Flutter / React Native for mobile apps, considering speed, scalability, and the benefit of one codebase serving multiple platforms.
Other technology stacks can be discussed and arranged upon request when you contact our team, ensuring they align with your internal preferences, compliance needs, and infrastructure choices.
Essential features to include
A strong Cohere-like MVP usually includes:
- “Chat with docs” assistant (RAG)
- Document upload + indexing pipeline
- Embeddings-based semantic retrieval
- Rerank step for better evidence selection
- Citations in answers (click to view source)
- Feedback buttons (helpful/not helpful) to improve quality
- Basic admin panel (users, workspaces, usage limits)
High-impact extensions later:
- Multi-department assistants (HR, IT, Finance, Legal)
- Workflow actions (create tickets, update CRM, generate reports)
- Evaluation suite (retrieval precision, hallucination checks)
- Advanced compliance (audit trails, policy controls)
Read More :- AI Chat Assistant Development Costs: What Startups Need to Know
Conclusion
Cohere’s biggest lesson is simple: enterprise AI wins when it’s trustworthy. The most valuable assistants aren’t the ones that sound the smartest—they’re the ones that consistently pull the right information, show where it came from, and behave predictably inside real business workflows.
If you’re building in this space, focus less on “a chatbot” and more on the system around it: retrieval quality, reranking, citations, governance, and cost control. That’s the difference between a fun demo and a platform companies will actually pay for.
FAQs :-
How does Cohere make money?
Cohere makes money through usage-based API pricing for its models (generation, embeddings, reranking) and through enterprise contracts for secure, private, and scalable deployments.
Is Cohere available in my country?
Cohere is a cloud-based platform, so availability typically depends on regional support, compliance requirements, and your account access. The most accurate check is Cohere’s official availability and onboarding flow for your region.
How much does Cohere charge users?
Cohere pricing depends on what you use. Generative models are usually priced by tokens (input and output can be priced differently). Embeddings are priced by tokens embedded. Rerank is commonly priced by the number of rerank requests/searches.
What’s the commission for service providers?
Cohere is not a marketplace, so there is no commission model. Costs are based on usage (tokens, embeddings volume, rerank requests) and any enterprise deployment terms.
How does Cohere ensure safety?
Cohere supports safer enterprise adoption through deployment patterns that reduce hallucinations, especially retrieval-augmented generation (RAG) with citations. In practice, safety is shared: Cohere provides models and guidance, while product teams implement access control, content policies, logging, and human review where needed.
Can I build something similar to Cohere?
Yes, but building a full Cohere-like platform requires multiple components: a generation layer, embeddings for retrieval, reranking for relevance, a RAG pipeline, citations/traceability, admin governance, monitoring, and cost controls.
What makes Cohere different from competitors?
Cohere is strongly positioned around enterprise use cases where reliability matters. Its focus on embeddings + rerank + RAG workflows and citation-style grounding makes it well-suited for business assistants that must be accurate and verifiable.
How many users does Cohere have?
Cohere does not consistently publish a single public “user count” metric. Adoption is often reflected through enterprise customers, production deployments, and reported revenue traction rather than a consumer-style user number.
What technology does Cohere use?
Cohere provides an API stack that typically includes generative language models, embedding models for semantic retrieval, reranking models to improve relevance, and RAG patterns that combine retrieval with grounded generation.
How can I create an app like Cohere?
To create a Cohere-like product, start with a focused use case such as “chat with company documents.” Build ingestion and chunking, store embeddings in a vector database, rerank results before generation, generate answers with citations, then add governance, monitoring, and billing. Miracuves can accelerate this with ready-to-launch architecture and customization for your niche.