




Imagine you’re building an AI feature inside your app—maybe a customer-support assistant, a “chat with PDFs” tool, or a smart writing helper. You want something powerful, but you also want flexibility: the ability to run it on your own infrastructure, tune it for your industry, and avoid being locked into one vendor forever.
That’s where Meta LLaMA comes in.
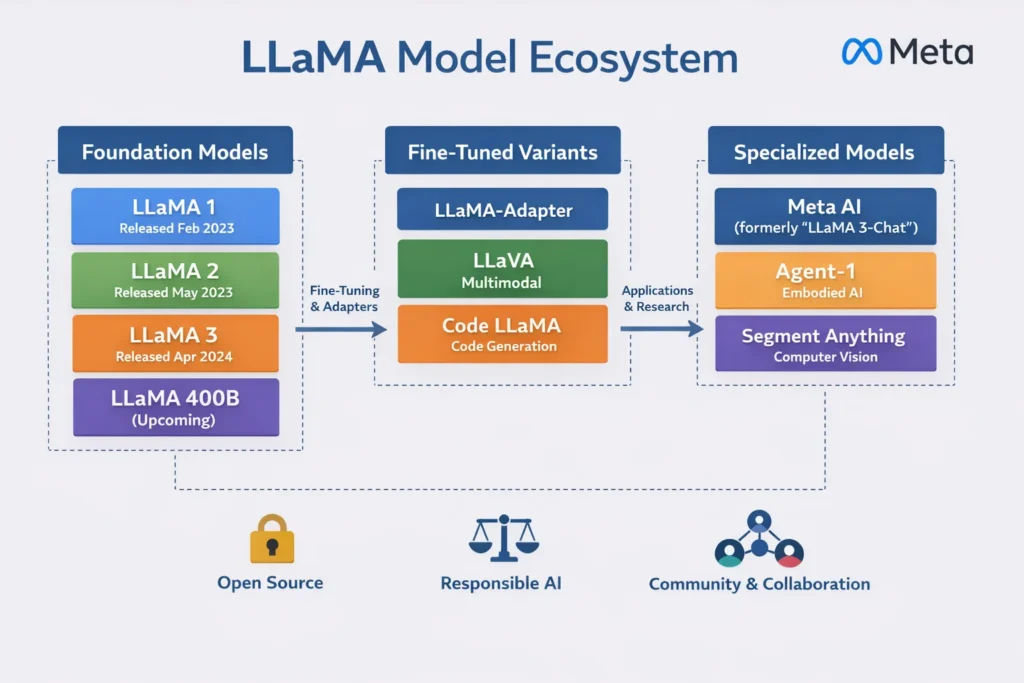
Meta LLaMA is a family of large language models released by Meta Platforms and distributed under a community license, designed to be used by developers and organizations for building AI applications. You can download model weights, follow official model cards/prompt formats, and deploy in multiple environments depending on your needs.
Quick origin story: LLaMA evolved rapidly through major releases like Llama 3.1 (with 8B, 70B, and 405B variants) and Llama 3.2 (adding lightweight models and vision-capable variants). More recently, reporting in 2025 highlighted the launch of Llama 4 variants (Scout and Maverick), signaling Meta’s push toward multimodal, high-performance open model systems.
By the end of this guide, you’ll understand what Meta LLaMA is, how it works step by step, how its licensing and ecosystem fit together, what features make it successful, and what it takes to build a LLaMA-powered product—or even a LLaMA-like platform—with Miracuves.
What is Meta LLaMA? The Simple Explanation
Meta LLaMA is a family of large language models from Meta that developers can use to build AI features like chatbots, writing assistants, document Q&A, summarization, and code helpers. The big difference versus many “closed” AI platforms is that Meta provides model weights (via official download channels/partners), so teams can run LLaMA on their own infrastructure and customize how it behaves.
The core problem it solves
Most businesses want AI, but they want flexibility:
- Control over hosting (cloud, on-prem, hybrid)
- The ability to fine-tune or adapt models for their domain
- Cost control at scale
- Less vendor lock-in
LLaMA supports this by giving organizations models they can deploy in different environments, instead of forcing everyone through a single hosted API.
Target users and use cases
Meta LLaMA is commonly used by:
- Product teams building AI features into SaaS apps
- Enterprises that need more control over deployment and data handling
- Developers experimenting with open-weight LLMs
Typical use cases: chat assistants, “chat with documents” (RAG), content generation, internal copilots, and AI search experiences.
Current market position with stats
Meta continues to expand the LLaMA lineup with newer generations (for example, the Llama 4 series) and has positioned it as a major open-weight ecosystem with official access and partner distribution.
Why it became successful
- Strong “open-weight” distribution approach (downloadable models + broad ecosystem)
- Multiple model options across sizes and capabilities (so teams can choose speed vs quality tradeoffs)
- A growing safety and safeguards toolkit (Llama Guard family and protections guidance)
How Does Meta LLaMA Work? Step-by-Step Breakdown
For users (developers, product teams)
Account creation process
Meta LLaMA isn’t a single “sign up and use” app like Uber. It’s a model family you access by getting the model files (weights) and then running them in your environment (or via a partner platform). A typical start looks like this:
- Request/download access to the models through Meta’s official flow or approved download partners.
- Accept the applicable LLaMA Community License agreement.
- Choose your deployment route: local inference, cloud deployment, or an ecosystem partner that hosts LLaMA for you.
Main features walkthrough (what you can do with LLaMA)
Once you have a LLaMA model running, you typically use it for:
- Chat and Q&A (assistants, copilots)
- Summarization and rewriting
- Structured extraction (turn messy text into clean fields)
- “Chat with documents” using RAG (retrieval + grounded answers)
- Multimodal use cases when using models that support vision/audio inputs (depends on the LLaMA generation/model variant).
Typical user journey (simple example)
Let’s say you want a “Support Assistant” for your SaaS:
- You collect your help-center articles and product docs
- You chunk them into small passages and index them in a vector database
- When a user asks a question, your system retrieves the most relevant passages
- You pass the question + those passages into LLaMA
- LLaMA drafts a grounded response that your support agent reviews or sends
That pattern is popular because it improves accuracy and keeps answers tied to real sources (instead of guessing).
Key functionalities explained (in plain English)
- Inference: you give the model text; it predicts the next words and generates a response.
- Fine-tuning (optional): you adapt the model to your domain tone/style using your own data (useful for niche assistants).
- Guardrails: you add safety checks around the model’s inputs and outputs to reduce risky content in production.
For service providers (companies building products on LLaMA)
Onboarding process
If you’re the “service provider” (you’re building the app), onboarding usually means:
- Select the model size that fits your product needs (speed vs quality vs cost).
- Decide where to run it (your servers, a cloud GPU provider, or a managed service).
- Set up monitoring, rate limits, and security (because LLaMA is now part of your production stack).
How they operate on the platform
Most LLaMA-powered products operate with a pipeline approach:
- Retrieval layer (search your knowledge) → LLaMA generation layer (write the answer)
- Optional reranking and citation mapping if you want enterprise-level trust signals
- Continuous evaluation (feedback loop) so the assistant improves over time
Earnings/Commission structure
There is no marketplace commission because LLaMA is a model, not a platform marketplace. Your costs are mostly:
- Infrastructure (GPU/CPU hosting)
- Engineering (deployment, monitoring, tuning)
- Compliance/security (if your domain requires it)
And your revenue comes from how you package it (subscription, per-seat, usage add-on).
Technical overview (simple)
Think of Meta LLaMA as a “brain” you can run in different places:
- You download the model (weights) under the license.
- You run it using an inference stack (local or cloud).
- Your app sends prompts/messages → model generates outputs → your app returns results to users.
- For more reliability, you wrap it with retrieval (RAG) and safety tools like Llama protections.
Read More :- How to Develop an AI Chatbot Platform
Meta LLaMA’s Business Model Explained
How Meta LLaMA “makes money” (what’s actually going on)
Meta LLaMA is different from typical AI startups because Meta doesn’t rely only on “API revenue” as the main story. Meta’s strategy is more ecosystem-driven:
- Ecosystem adoption (distribution + influence)
Meta releases LLaMA models under a community license that allows broad use, which helps make LLaMA a default option across the AI ecosystem. This drives standardization, mindshare, and developer loyalty. - Platform expansion via the Llama API and Meta AI experiences
Meta launched a Llama API (in limited preview at launch) to attract businesses that want a hosted API experience rather than self-hosting, putting it into more direct competition with other API providers. - Indirect monetization through Meta’s broader business
Even when LLaMA itself is licensed royalty-free, it strengthens Meta’s broader AI stack (Meta AI, developer ecosystem, and AI features across Meta products). This can support product engagement and ad-driven value indirectly, even if the model weights are distributed widely.
Licensing and usage restrictions (important for businesses)
LLaMA is often described as “open,” but it’s governed by a community license that includes conditions and restrictions. For example, the Llama license terms are published by Meta for different generations (e.g., Llama 3.2 and Llama 4 licenses).
There has also been public criticism from open-source organizations arguing the license does not meet the Open Source Definition due to restrictions (including clauses that impact very large entities).
Pricing structure (where costs show up in the real world)
Because LLaMA can be used in multiple ways, “pricing” depends on how you access it:
- Self-hosted LLaMA: your main cost is infrastructure (GPUs/CPUs), deployment engineering, monitoring, and compliance. The license itself is typically royalty-free under the published terms.
- Hosted via a cloud platform: you pay the platform’s token-based or usage-based pricing. For example, Amazon Bedrock provides pricing tables for Meta models (priced per 1,000 input/output tokens, varying by model and region).
- Meta’s Llama API: governed by Meta’s Llama API Terms of Service (business terms + platform access rules).
Fee breakdown (what you’re effectively paying for)
There’s no “commission” like a marketplace. Costs typically break into:
- Compute (GPU time / token processing)
- Storage + bandwidth for model artifacts and logs
- Engineering (RAG, evaluation, guardrails, monitoring)
- Vendor/platform fees (only if using a hosted service like Bedrock or another provider)
Market size and growth signals
A major growth signal is that Meta keeps expanding the LLaMA lineup (e.g., Llama 4 series reported in 2025) and is also pushing an official API to make enterprise adoption easier.
Revenue model breakdown
| Revenue stream / value path | What it includes | Who pays | How it scales |
|---|---|---|---|
| Community license adoption | Broad use of LLaMA under published license terms | No direct fee in many cases | Scales via ecosystem and distribution |
| Llama API (hosted) | Hosted access under Meta’s API terms | Developers & businesses | Scales with usage and enterprise adoption |
| Cloud marketplace hosting | LLaMA served through cloud platforms | Customers of the cloud platform | Scales with token usage (cloud pricing) |
| Indirect Meta product value | AI features across Meta apps and services | Advertisers/users (indirect) | Scales with engagement and product adoption |
Key Features That Make Meta LLaMA Successful
1) Open-weight model releases (you can actually run it yourself)
Why it matters: Many companies don’t want to depend on a single hosted vendor for every AI request.
How it benefits users: You can deploy on your own infrastructure (cloud, on-prem, hybrid), control latency/cost, and customize behavior.
Technical innovation involved: Meta distributes model weights and official model documentation so teams can run and integrate LLaMA directly.
2) A wide range of model sizes for speed vs quality tradeoffs
Why it matters: Not every product needs a “giant” model—sometimes you need fast, cheap inference at scale.
How it benefits users: You can choose smaller models for mobile/edge or high-throughput apps, and bigger ones for quality-critical tasks.
Technical innovation involved: Llama 3.1 released 8B/70B/405B variants, and Llama 3.2 added lightweight 1B/3B models for edge use cases plus vision-capable models.
3) Long context support for “real documents” and enterprise workflows
Why it matters: Real business tasks involve long PDFs, policies, manuals, and multi-turn conversations.
How it benefits users: Better document Q&A, better summaries, and fewer “I forgot what you said earlier” failures.
Technical innovation involved: Llama 3.1 emphasized long context capabilities (and ecosystem deployments highlighted this for production usage).
4) Natively multimodal direction (text + more than text)
Why it matters: Modern products need AI that can work with images (and increasingly other modalities) instead of only text.
How it benefits users: You can build features like image understanding, multimodal assistants, and richer “chat with media” workflows.
Technical innovation involved: Llama 3.2 introduced vision LLM variants (11B/90B), and Llama 4 was presented as a natively multimodal system with Scout and Maverick variants.
5) Strong safety tooling with Llama Guard safeguard models
Why it matters: Production AI needs guardrails for harmful prompts and risky outputs.
How it benefits users: Safer deployments, fewer policy violations, and better control when your app is exposed to the public.
Technical innovation involved: The Llama Guard family provides input/output safeguard models with documented prompt formats; newer iterations (e.g., Llama Guard 3 and Llama Guard 4) extend capability and coverage.
6) Broad ecosystem distribution across major clouds and platforms
Why it matters: Adoption accelerates when models are easy to access where teams already build and deploy.
How it benefits users: Faster time-to-production because you can use LLaMA through familiar cloud AI services instead of setting up everything from scratch.
Technical innovation involved: Major clouds integrated Llama 3.1 and Llama 3.2 (for example, availability via managed services like Amazon Bedrock).
7) A growing “official API” path for teams that don’t want to self-host
Why it matters: Some businesses want open-weight flexibility, but still prefer a hosted API for speed and simplicity.
How it benefits users: You can start quickly via an API, then later migrate to self-hosting if needed (or mix both).
Technical innovation involved: Meta introduced a Llama API effort (reported in 2025) aimed at attracting developers and businesses.
8) Clear licensing terms that enable broad commercial use (with conditions)
Why it matters: Businesses can’t adopt models if licensing is uncertain.
How it benefits users: Teams can evaluate whether LLaMA fits their legal/commercial needs early, before engineering investment.
Technical innovation involved: Meta publishes the LLaMA community license and related documentation; it’s widely used but also debated in the open-source community.
9) Strong technical documentation (model cards, prompt formats, protections)
Why it matters: The gap between “having weights” and “shipping a product” is docs, evaluation, and operational guidance.
How it benefits users: Faster implementation, fewer integration mistakes, and better safety configuration.
Technical innovation involved: Official model cards and prompt formats (including safeguard prompts) are published and updated as the model family evolves.
10) Constant iteration + high-profile releases that keep the ecosystem moving
Why it matters: AI moves fast; platforms that stall lose developers quickly.
How it benefits users: More choices, better performance, and newer capabilities without switching ecosystems.
Technical innovation involved: Rapid releases from Llama 3.1 → 3.2 → Llama 4 variants (Scout, Maverick) show sustained investment and expansion.
The Technology Behind Meta LLaMA
Tech stack overview (simplified)
Meta LLaMA is best thought of as a “model family” you can run in different places, not a single app. The core technology is the LLaMA model itself (the language model weights), plus the surrounding tools that make it usable and safer in real products—things like prompt formats, guardrails, and deployment options.
Real-time features explanation (how LLaMA powers live apps)
When someone chats with a LLaMA-powered assistant, the experience feels instant—but behind the scenes it’s a fast loop: the user sends a message, your backend packages it into the right prompt format, the model generates tokens (words) one after another, and your app streams the output back to the screen.
If you’re building “chat with documents,” you usually add one extra step before the model answers: retrieve the best matching document snippets from your knowledge base, then provide those snippets to LLaMA as context. That’s how teams get more accurate, less “guessy” answers in production.
Model sizes and deployment choices (why it matters for product teams)
LLaMA’s ecosystem supports different sizes and generations, which gives teams a real business advantage: you can choose a smaller model for speed and cost, or a bigger one when quality matters most. Many teams also avoid “one size fits all” by using smaller models for everyday tasks and larger models only for high-value requests.
And deployment is flexible: you can self-host, or use managed platforms that already provide LLaMA as an option. Amazon Bedrock, for example, announced general availability for Llama 3.1 (8B/70B/405B) and later added Llama 3.2 model options, which makes it easier to deploy without managing everything yourself.
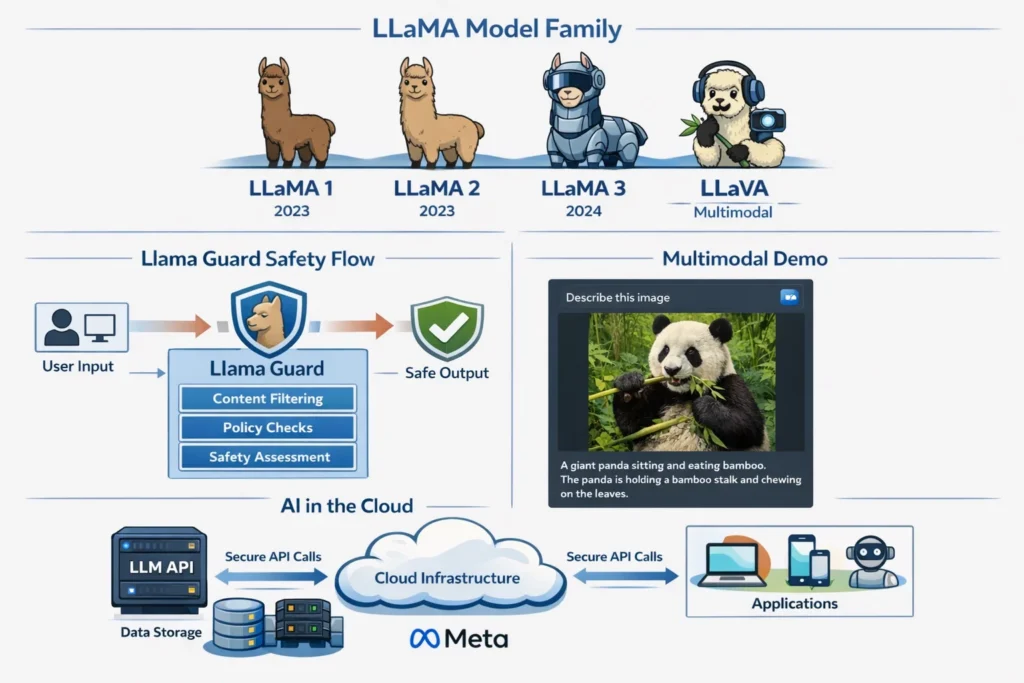
Multimodal direction (text + images and more)
Modern AI products increasingly need to handle more than text. Meta announced Llama 3.2 as including vision-capable models (11B and 90B) and lightweight text-only models (1B and 3B).
Reuters also reported that Meta released Llama 4 variants and described Llama as a multimodal system capable of integrating multiple data types.
What this means for builders: you can design assistants that don’t just read text—they can also interpret images (depending on the model variant you choose).
Safety, guardrails, and “protections” (what makes it production-ready)
In real-world apps, safety isn’t optional. Meta’s LLaMA ecosystem includes guardrail-style models like Llama Guard that can classify prompts and responses to help filter unsafe content before it reaches users.
There are also prompt-focused protection models like Prompt Guard, designed to help detect prompt injection or malicious instructions.
In simple terms: you can put a “security checkpoint” before and after the main model call—so your app is safer by design.
Data handling and privacy (how teams typically implement it)
Because LLaMA can be self-hosted, many teams use it when they want stronger control over data flow. A common pattern is: keep documents and user data inside your environment, retrieve only what’s necessary, and send minimal context to the model. This is also why enterprise teams like RAG: it helps accuracy while keeping sensitive data exposure limited.
Mobile app vs web platform (practical architecture)
Most LLaMA-powered products follow a safe architecture: the mobile/web app never talks to the model directly. Instead, your backend handles authentication, retrieval, policy checks, and then calls the model (self-hosted or via a managed service). That keeps your keys safe, enforces permissions, and gives you cost control.
API integrations (how LLaMA becomes “a real product feature”)
LLaMA becomes much more valuable when connected to real systems: knowledge bases, support tickets, CRM notes, product docs, and internal tools. If you’re using managed platforms like Bedrock, AWS even positions Knowledge Bases + LLaMA as a practical RAG path for enterprise data connections.
Why this tech matters for business
The key benefit is flexibility. With LLaMA, you can choose your hosting approach, control costs, tune behavior, and add guardrails—so AI becomes something you can operate like a real system, not just a demo.
Meta LLaMA’s Impact & Market Opportunity
Industry disruption it caused
Meta LLaMA helped make “open-weight” language models mainstream for product teams. Instead of every company being forced into a single closed API vendor, LLaMA made it normal to say: “We’ll run the model ourselves (or via a cloud marketplace) and keep control over cost, latency, and data.” That shift is a big deal for enterprises and startups building long-term AI products.
Meta also pushed the category forward by moving beyond text-only models. Llama 4 was introduced as a multimodal system, and Meta described the Scout and Maverick variants as part of that next wave.
Market statistics and growth signals
A strong growth signal is Meta’s continued investment in new LLaMA generations and distribution. Reuters reported Meta released Llama 4 Scout and Llama 4 Maverick and positioned Llama as multimodal.
Another big signal is Meta adding a more “enterprise-friendly” access path: Reuters reported Meta introduced a Llama API (limited preview at launch), aiming to attract businesses and compete with other major API providers.
User demographics and behavior
LLaMA’s adoption tends to come from a few groups:
- Builders who want flexible deployment (self-host or cloud)
- Companies that want to fine-tune or customize behavior
- Teams that care about cost control at scale
- Org/security teams that prefer keeping more data inside their environment
A common behavior pattern is “start with managed hosting to ship fast → move to self-hosting when usage grows and costs/controls matter more.”
Geographic presence
LLaMA is used globally, but an interesting recent development is broader availability for government and allied institutions. Reuters reported Meta’s Llama being approved for U.S. government agency use and also being made accessible to U.S. allies in Europe and Asia (with partnerships involving major tech firms).
Future projections
Where this is heading is pretty clear:
- More multimodal assistants (text + images, and beyond) as model families evolve
- More official “easy mode” access via hosted APIs (for teams that don’t want infra)
- More safety-by-default deployments using guardrail models like Llama Guard (to reduce risky outputs in production)
Opportunities for entrepreneurs
This massive success is why many entrepreneurs want to create similar platforms—because there’s huge demand for products that package open models into something businesses can actually use. Some strong opportunities:
- Vertical copilots (legal, HR, insurance, logistics) that run on open-weight models for cost and control
- “Chat with documents” products for SMEs that need private, grounded answers
- Safety-first AI stacks that bundle guardrails + monitoring + governance as a product
- Managed deployment layers for open models (one-click hosting, scaling, observability)
This massive success is why many entrepreneurs want to create similar platforms…
Building Your Own Meta LLaMA–Like Platform
Why businesses want LLaMA-style (open-weight) AI platforms
Businesses want LLaMA-style platforms because they want flexibility and control. Instead of being locked into one vendor’s hosted API, they can choose how to deploy, how to secure data, and how to optimize cost at scale. The open-weight model approach also makes it easier to customize behavior for specific industries like insurance, fintech, healthcare, logistics, and education.
Key considerations for development
To build a LLaMA-like platform, the biggest design choice is whether you’re offering a “self-hosted toolkit” experience, a hosted API experience, or both. Then you need to make it production-ready: permissions, monitoring, guardrails, evaluation, and reliable retrieval pipelines (RAG) so answers stay grounded in real data instead of guessing.
Read Also :- How to Market an AI Chatbot Platform Successfully After Launch
Cost Factors & Pricing Breakdown
Meta LLaMA–Like App Development — Market Price
| Development Level | Inclusions | Estimated Market Price (USD) |
|---|---|---|
| 1. Basic LLM Deployment & Chat MVP | Core web chat interface, user registration & login, integration with a single hosted/open-source LLM (e.g., LLaMA via your chosen hosting), prompt → response flow, basic conversation history, simple moderation hooks, basic admin panel, usage analytics | $90,000 |
| 2. Mid-Level LLM Platform & API Layer | Multi-model support (chat + embeddings), API endpoints (chat/completions/embeddings), workspace/projects, API key management, rate limiting & quotas, usage dashboards, basic RAG/document upload, credits/usage tracking, stronger safety & moderation hooks, polished web UI and developer console | $190,000 |
| 3. Advanced Meta LLaMA–Level Foundation Model Ecosystem | Large-scale multi-tenant LLM platform with high-throughput inference infrastructure, fine-tuning pipelines (LoRA/adapters), model/version management, enterprise orgs & RBAC/SSO, audit logs, advanced observability, policy enforcement, cloud-native scalable architecture, developer ecosystem features and integrations | $320,000+ |
Meta LLaMA-Style Foundation Model Platform Development
The prices above reflect the global market cost of developing a Meta LLaMA-style foundation model platform — typically ranging from $90,000 to over $320,000+, with a delivery timeline of around 4–12 months for a full, from-scratch build. This usually includes model hosting or integration, inference APIs, developer tooling, usage metering, governance controls, and production-grade infrastructure designed for high-throughput AI workloads.
Miracuves Pricing for a Meta LLaMA–Like Custom Platform
Miracuves Price: Starts at $15,999
This is positioned for a feature-rich, JS-based Meta LLaMA-style AI platform that can include:
- Chat and inference APIs using your chosen LLaMA hosting/provider setup
- Multi-model endpoints (chat + embeddings) with API keys, quotas, and rate limits
- User accounts, projects/workspaces, and access controls
- Basic RAG/document ingestion workflows.
- Usage tracking with optional subscription or credit-based billing
- Core moderation, compliance, and safety hooks
- A modern, responsive web interface plus optional companion mobile apps
From this foundation, the platform can be extended into fine-tuning workflows, enterprise governance, audit trails, advanced observability, and large-scale multi-tenant SaaS deployments as your AI ecosystem matures.
Note: This includes full non-encrypted source code (complete ownership), complete deployment support, backend & API setup, admin panel configuration, and assistance with publishing on the Google Play Store and Apple App Store—ensuring you receive a fully operational AI platform ecosystem ready for launch and future expansion.
Delivery Timeline for a Meta LLaMA–Like Platform with Miracuves
For a Meta LLaMA-style, JS-based custom build, the typical delivery timeline with Miracuves is 30–90 days, depending on:
- Depth of model endpoints, routing, and RAG/fine-tuning requirements
- Number and complexity of hosting, storage, billing, and moderation integrations
- Complexity of enterprise features (RBAC, SSO, governance, audit logs)
- Scope of web portal, mobile apps, branding, and long-term scalability targets
Tech Stack
We preferably will be using JavaScript for building the entire solution (Node.js / Nest.js / Next.js for the web backend + frontend) and Flutter / React Native for mobile apps, considering speed, scalability, and the benefit of one codebase serving multiple platforms.
Other technology stacks can be discussed and arranged upon request when you contact our team, ensuring they align with your internal preferences, compliance needs, and infrastructure choices.
Essential features to include
- Model access layer: download flow or hosted API gateway
- Secure authentication: API keys, OAuth/SSO options, token rotation
- Usage controls: rate limits, quotas, per-tenant usage tracking
- Multi-tenant workspace system: orgs, teams, roles, permissions (RBAC)
- Model catalog: multiple sizes/variants with clear “speed vs quality” guidance
- Inference serving: scalable hosting with autoscaling and regional deployment options
- Cost dashboard: token/compute reporting, budgets, alerts, per-feature spend
- RAG toolkit: document upload, chunking, embeddings, vector search, context assembly
- Reranking/evidence selection: improve relevance before generation
- Citations/sources in answers: clickable proof for enterprise trust
- Safety layer: prompt injection detection + content policy checks (guardrail models)
- Evaluation loop: human feedback, quality scoring, regression testing for prompts/models
- Logs and observability: latency, error tracking, model drift, output monitoring
- Developer tools: SDKs, templates, sandbox environment, sample apps
Read More :- AI Chat Assistant Development Costs: What Startups Need to Know
Conclusion
Meta LLaMA’s biggest impact is that it made advanced AI feel “deployable” for everyone—not just teams who can afford massive proprietary contracts. By offering open-weight models and expanding the ecosystem through cloud partnerships and safety tooling, it gave builders real control over where AI runs, how it’s governed, and how costs behave at scale.
If you’re building in this space, the real competitive advantage isn’t just model quality. It’s the complete system around the model: retrieval that keeps answers grounded, guardrails that keep users safe, monitoring that keeps quality stable, and cost controls that keep the product profitable.
FAQs :-
How does Meta LLaMA make money?
Meta LLaMA is primarily an ecosystem strategy. Many uses are enabled under Meta’s community license, while Meta also introduced a Llama API path to attract developers who want hosted access. Meta can also benefit indirectly through broader product adoption and AI capabilities across its ecosystem.
Is Meta LLaMA available in my country?
LLaMA models are distributed through official access flows and partners. Availability is generally broad, but specific access can depend on the model generation, licensing terms, and the channel you use to obtain or run it.
How much does Meta LLaMA charge users?
If you self-host, you generally don’t pay Meta per request; your costs are infrastructure (GPUs), engineering, and operations. If you use a hosted cloud service or hosted API route, pricing is determined by that provider’s token/usage rates.
What’s the commission for service providers?
There is no commission model. LLaMA is a model family, not a marketplace. You monetize your product the way you choose (subscription, per-seat, usage add-on).
How does Meta LLaMA ensure safety?
LLaMA deployments typically combine model behavior controls with safety tools. Meta provides safeguard models like Llama Guard and prompt-injection oriented tools like Prompt Guard, and teams add additional policies, filters, and monitoring around their product.
Can I build something similar to Meta LLaMA?
You can build a platform around open-weight models, but building a full “LLaMA-like ecosystem” is a big project. You’d need model access/distribution, serving infrastructure, safety guardrails, retrieval tooling, monitoring, billing, and developer experience.
What makes Meta LLaMA different from competitors?
Its core difference is open-weight availability paired with a massive ecosystem. That gives businesses flexibility in hosting, customization, and cost control compared to purely closed, hosted-only platforms.
How many users does Meta LLaMA have?
Meta doesn’t publish one universal “user count” for LLaMA because it’s used across many channels (self-hosted deployments, cloud platforms, and various integrations). Adoption is better measured by ecosystem footprint and enterprise usage rather than a single app metric.
What technology does Meta LLaMA use?
Meta LLaMA is a family of large language models designed for text generation and related tasks. The ecosystem includes official model documentation, prompt formats, and safety models such as Llama Guard, plus multiple deployment paths (self-hosted or via cloud platforms).
How can I create an app like Meta LLaMA?
Start by choosing an open-weight model, deploying it on secure infrastructure, then adding a retrieval layer (RAG) for grounded answers, safety guardrails, monitoring, and cost controls. Miracuves can accelerate this with ready-to-launch modules for multi-tenant AI platforms, RAG pipelines, admin governance, and subscription billing.




