Modern video platforms process far more than uploaded media files. Every swipe, replay, pause, comment, share, follow, and like continuously generates new engagement signals that must be processed almost instantly across the platform. In high-growth short-video ecosystems, millions of interaction events can occur within minutes, especially when viral content begins spreading rapidly across recommendation feeds.
This creates a very different infrastructure challenge compared to traditional web applications. Video platforms are not simply serving static content from databases. They are operating real-time engagement ecosystems where recommendation systems, analytics engines, moderation workflows, and feed-ranking models constantly depend on fresh behavioral data.
As traffic increases, poorly designed databases begin creating operational problems very quickly. Feed loading becomes inconsistent, recommendation refresh rates slow down, engagement counters lose synchronization, and analytics pipelines fall behind during viral spikes. These issues directly affect user retention because short-video platforms rely heavily on responsiveness and continuous personalization.
This is why scalable database architecture has become one of the most important technical foundations behind modern TikTok-like ecosystems where recommendation systems, engagement processing, and feed responsiveness must scale continuously.”
For businesses building video platforms, database architecture is no longer just backend engineering. It directly influences recommendation quality, platform stability, creator engagement, and long-term scalability.
The Real Numbers Behind Short-Video Platform Infrastructure

The numbers behind modern short-video infrastructure are significantly larger than most traditional applications. Recommendation feeds, engagement systems, and real-time analytics pipelines continuously process millions of requests simultaneously, especially during viral traffic spikes. These scale requirements explain why distributed database architecture has become essential for high-growth video platforms.
| Infrastructure Metric | Estimated Scale |
|---|---|
| Daily Active Users | 10M–100M+ |
| Feed Read Requests | 500K–2M QPS |
| Engagement Writes | 50K–500K writes/sec |
| Daily Video Uploads | 10TB–1PB+ |
| Watch-Time Events | Billions per day |
| Peak Outbound Bandwidth | Multi-Tbps globally |
These numbers explain why modern short-video platforms cannot depend on traditional centralized databases alone. Recommendation systems, engagement pipelines, and feed infrastructure must all scale horizontally while maintaining low-latency responsiveness during unpredictable viral traffic spikes.
Why Short-Video Platforms Break Databases That Work Fine Elsewhere
Most traditional applications handle predictable user behavior. Video ecosystems behave very differently because engagement activity never truly stops while users remain inside the feed.
A single user session can generate:
- Multiple watch-duration updates as users scroll rapidly through short-form content while recommendation systems continuously adjust feed rankings in real time.
- Replay signals, likes, comments, follows, and shares that instantly influence personalization models and engagement-scoring systems.
- Continuous metadata retrieval requests for creator profiles, video information, captions, hashtags, thumbnails, and recommendation candidates.
Unlike standard social applications, short-video platforms must process both extremely high read traffic and extremely high write traffic simultaneously.
| System Pressure Area | Why It Scales Rapidly |
|---|---|
| Engagement Writes | Every interaction continuously updates recommendation signals |
| Feed Queries | Personalized feeds require constant metadata retrieval |
| Analytics Events | Watch-time tracking creates massive behavioral datasets |
| Recommendation Processing | User behavior continuously changes ranking logic |
| Global Distribution | Users expect low-latency playback across regions |
Read-Heavy vs Write-Heavy Workloads
| Read-Heavy Operations | Write-Heavy Operations |
|---|---|
| Feed retrieval | Likes and reactions |
| Metadata loading | Watch-time tracking |
| Search queries | Comment submissions |
| Creator profile requests | Recommendation signal updates |
Video platforms must optimize both workload types simultaneously because recommendation feeds continuously depend on real-time engagement synchronization.
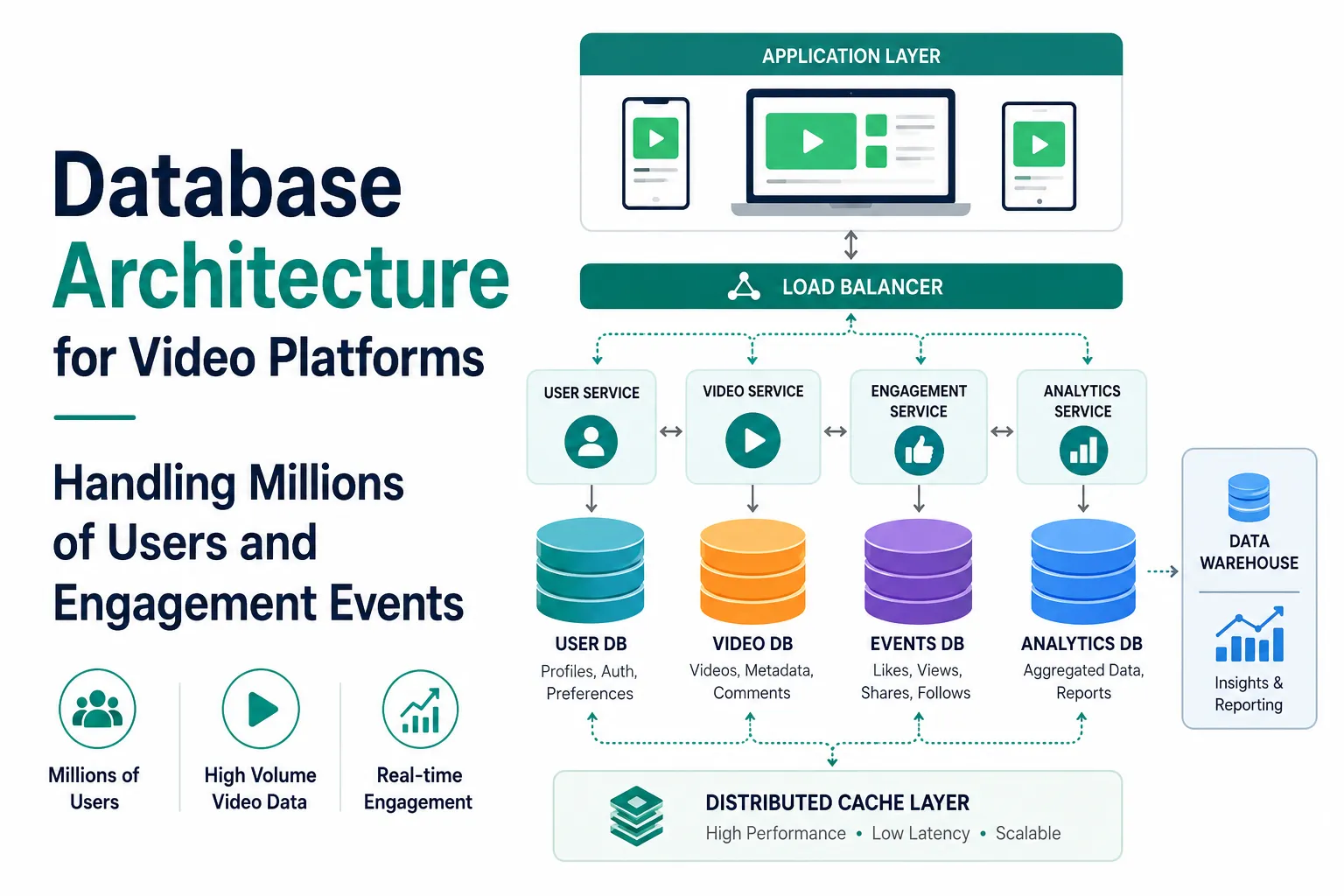
The 3 Core Database Layers Every Large Video Platform Must Separate
Most high-growth short-video ecosystems divide infrastructure into multiple database layers instead of relying on one centralized system.
This separation helps platforms isolate traffic patterns and reduce performance bottlenecks during viral engagement spikes.
User Relationship Infrastructure
User databases usually depend on systems like PostgreSQL because account-level consistency is extremely important. These databases store authentication credentials, creator settings, follow relationships, moderation controls, personalization preferences, and session history.
Recommendation systems also rely heavily on relationship mapping because creator interactions, viewing behavior, and social graph activity continuously influence feed personalization.
Video Metadata Infrastructure
Metadata layers often use PostgreSQL with read replicas to improve large-scale retrieval performance across recommendation feeds.
These systems store captions, hashtags, thumbnails, creator IDs, moderation status, upload timestamps, visibility settings, and engagement counters. Since feed services continuously request metadata before playback begins, this layer experiences extremely high read traffic throughout the platform.
Poor metadata optimization often causes delayed feed rendering and inconsistent scrolling responsiveness during viral spikes.
Engagement Event Infrastructure
The engagement layer handles the largest amount of write-heavy traffic across the platform.
Every swipe, replay, watch-duration update, comment, reaction, follow action, and share continuously generates new events during active feed consumption.
Large-scale platforms often use Cassandra or DynamoDB for engagement ingestion because relational systems struggle with massive real-time write amplification. Apache Kafka or AWS Kinesis pipelines are also commonly used to process engagement events asynchronously before synchronization occurs.
From 0 to 1 Million Requests in Minutes: How Viral Traffic Breaks Monolithic Databases
Many startups initially launch using one centralized relational database because it simplifies development during early growth stages. This approach usually works temporarily while traffic remains relatively small and user activity stays predictable.
However, short-video ecosystems scale very differently from conventional applications because recommendation systems on platforms like TikTok can suddenly expose content to millions of users within minutes.
This creates several operational problems:
- Large engagement tables grow rapidly into billions of rows, making aggregation queries increasingly expensive for analytics systems and recommendation engines.
- Continuous write amplification slows feed responsiveness because recommendation updates and engagement synchronization compete for database throughput.
- Hot shard problems begin appearing when viral creators generate uneven traffic distribution across infrastructure partitions.
- Analytics pipelines become overloaded because watch-duration tracking and retention events generate enormous amounts of behavioral data continuously.
- Global audiences experience latency increases when centralized databases force every request through one infrastructure region.
As traffic scales further, recommendation systems begin generating extremely uneven infrastructure pressure because a small percentage of viral content suddenly receives massive engagement concentration. This makes centralized architectures increasingly unstable during high-volume traffic spikes.
Vertical scaling alone eventually becomes inefficient because hardware limits cannot sustainably handle unpredictable viral engagement spikes. Modern short-video ecosystems therefore depend heavily on distributed scaling strategies, event pipelines, sharding systems, and caching infrastructure long before they reach global traffic levels.
How Sharding Prevents One Viral Creator From Crashing Your Platform
Sharding divides large datasets across multiple database nodes so traffic can scale horizontally instead of overwhelming one centralized system.
Most large video ecosystems combine multiple sharding strategies together depending on traffic behavior and recommendation patterns.
| Sharding Strategy | Practical Usage |
|---|---|
| User-ID Sharding | Distributes engagement traffic across user partitions |
| Regional Sharding | Reduces latency for international audiences |
| Creator-Based Sharding | Isolates high-traffic creator workloads |
| Hash-Based Sharding | Balances write operations across clusters |
Regional sharding helps reduce latency for global users, while hash-based distribution improves infrastructure stability during sudden viral spikes.
As recommendation systems scale, intelligent sharding becomes essential for maintaining feed responsiveness and engagement synchronization.
What Happens to Feed Speed When Indexing Is Done Wrong

Indexing directly affects how quickly recommendation systems retrieve personalized content across massive engagement datasets. Every time a user refreshes a feed, opens comments, searches hashtags, or interacts with creators, databases must retrieve highly relevant information within milliseconds. As interaction history grows into billions of records, poorly optimized indexes begin slowing recommendation pipelines significantly.
Without efficient indexing strategies, feed generation becomes increasingly unstable because recommendation engines repeatedly scan unnecessarily large datasets. This increases query latency, slows scrolling responsiveness, and delays personalization updates during high-traffic periods. In short-video ecosystems where users continuously swipe through content, even small delays can negatively affect retention and session duration.
Modern platforms commonly optimize indexes around:
- Personalized feed retrieval where recommendation systems continuously fetch watched history, creator interactions, and engagement-ranking signals.
- Comment systems that organize nested replies using timestamps, moderation status, popularity ranking, and discussion relationships.
- Discovery systems where hashtags, audio references, usernames, and trend categories require rapid search responsiveness during heavy traffic periods.
Efficient indexing improves feed refresh speed, recommendation latency, search quality, and scrolling smoothness simultaneously. It also reduces unnecessary infrastructure load because recommendation systems retrieve targeted datasets more efficiently instead of repeatedly scanning large database partitions.
Poor indexing, on the other hand, increases infrastructure pressure dramatically. Recommendation engines consume more compute resources, feed services respond slower during traffic spikes, and engagement synchronization becomes increasingly difficult as datasets continue scaling globally.
Choosing the Right Database for Each Layer of a Video Platform
Modern short-video platforms use multiple database systems because every infrastructure layer handles different workloads. Feed retrieval, engagement tracking, recommendation processing, and session caching all require different performance optimizations to maintain scalability and low-latency responsiveness.
| Workload Type | Best Database Choice | Why It Fits Video Platforms |
|---|---|---|
| User Profiles | PostgreSQL | Strong consistency and account reliability |
| Engagement Events | Cassandra / DynamoDB | Handles massive write-heavy workloads |
| Session Caching | Redis | Ultra-fast feed and session retrieval |
| Video Metadata | PostgreSQL + Read Replicas | Efficient structured querying |
| Recommendation Signals | Cassandra | Distributed behavioral data processing |
Most mature platforms combine multiple database systems together because no single infrastructure model can efficiently handle every workload type inside engagement-heavy ecosystems.
How Cassandra, DynamoDB, and Redis Each Solve Different Problems at Scale
Large-scale engagement ecosystems increasingly rely on specialized infrastructure because relational systems alone struggle with extremely high-volume event ingestion.
Cassandra is commonly used for distributed engagement workloads because it supports horizontal scaling and high write throughput across massive datasets.
DynamoDB is often useful for flexible schemas and rapid infrastructure scaling where recommendation signals evolve continuously.
Redis plays a different role. Instead of long-term storage, Redis-based distributed caching layers help platforms reduce latency by accelerating feed retrieval, recommendation sessions, and engagement counter visibility.
Modern platforms therefore separate responsibilities carefully rather than forcing one database technology to handle every infrastructure workload simultaneously.
How Event Pipelines Protect Core Databases
Modern video platforms rarely write every engagement action directly into long-term databases immediately.
Instead, engagement activity usually flows through Apache Kafka or AWS Kinesis event pipelines before synchronization occurs.
A simplified infrastructure workflow often looks like this:
User Action → API Gateway → Kafka Event Queue → Stream Processor → Redis Cache + Cassandra Engagement DB → PostgreSQL Metadata Layer → Recommendation Engine → Feed Response
This architecture provides several operational advantages:
- Viral engagement spikes become easier to absorb because traffic gets buffered before reaching core database systems.
- Recommendation engines receive behavioral updates faster without waiting for large synchronization operations.
- Analytics systems process watch-duration tracking asynchronously without slowing feed responsiveness.
- Stream-processing systems help isolate infrastructure workloads so recommendation pipelines and moderation systems can scale independently.
This type of architecture has become increasingly common across engagement-heavy video ecosystems.
How Redis Caching Keeps Recommendation Feeds Responsive at Millions of Requests
Recommendation systems repeatedly request similar datasets across millions of users simultaneously.
Without Redis caching layers, databases become overloaded very quickly because feed services continuously retrieve the same metadata, recommendation candidates, creator profiles, and engagement counters repeatedly.
Large-scale video platforms therefore cache:
- Trending video collections that receive extremely high traffic during viral distribution periods.
- Personalized feed sessions temporarily so scrolling remains responsive while reducing repeated database queries.
- Frequently accessed creator metadata and engagement counters that constantly appear across recommendation feeds.
Redis-based caching significantly reduces latency while improving overall infrastructure efficiency during high-volume traffic events.
Designing Like and Comment Systems for Massive Scale
Likes and comments may appear operationally simple from the user perspective, but they become highly complex infrastructure systems at scale.
Like systems must support rapid engagement synchronization, duplicate prevention, recommendation scoring integration, and real-time counter visibility simultaneously.
Many platforms therefore separate engagement writes from aggregated counter systems to reduce database pressure during viral activity.
Comment systems introduce even greater complexity because they require:
- Nested discussion handling where large conversation trees continuously grow during viral engagement spikes.
- Moderation pipelines capable of processing spam detection, abuse filtering, and policy enforcement asynchronously.
- Ranking systems that prioritize high-quality discussions without slowing feed infrastructure.
Large-scale platforms therefore isolate comment indexing and ranking into independent processing pipelines rather than attaching them directly to feed-generation systems.
Multi-Region Database Replication for Global Feed Consistency
As video platforms expand internationally, database replication becomes increasingly important for both reliability and regional responsiveness. Users expect recommendation feeds, engagement counters, and creator content to load quickly regardless of their geographic location. Without distributed replication, international audiences often experience higher latency and slower feed refresh performance.
Replication creates multiple synchronized copies of infrastructure across different geographic regions so platforms can distribute read traffic more efficiently. This helps reduce response times while also improving system stability during regional traffic spikes or infrastructure failures.
Many platforms separate workloads using:
- Primary-write databases for consistency-sensitive operations such as account management, engagement synchronization, and recommendation updates where data accuracy is extremely important.
- Read replicas for recommendation feeds, analytics queries, creator metadata retrieval, and high-volume feed generation requests that require fast regional access.
Cloudflare CDN and AWS CloudFront are also commonly integrated alongside replication layers to improve regional content delivery performance globally. Combined together, replication and distributed delivery systems help maintain smoother feed responsiveness for users across multiple countries simultaneously.
Replication also strengthens disaster recovery readiness because traffic can shift between infrastructure regions more efficiently if one system experiences failures or unexpected load spikes.
Protecting User Data and Engagement Integrity at Platform Scale
Short-video ecosystems process enormous amounts of behavioral and creator-related information continuously. Protecting this infrastructure becomes essential for platform trust and operational stability.
Important protection layers usually include:
- Role-based access systems that isolate internal permissions and reduce unauthorized infrastructure exposure risks.
- Encryption for authentication credentials, moderation-sensitive information, creator data, and user session tokens.
- Rate limiting mechanisms that reduce spam attacks, automated abuse, and fake engagement manipulation attempts.
- Audit logging systems that track moderation workflows, administrative actions, and infrastructure-level governance changes.
As recommendation ecosystems grow, database security becomes increasingly important for both user trust and advertiser confidence.
Common Database Mistakes Early Video Startups Make
Many early-stage video platforms underestimate how quickly engagement infrastructure complexity grows once recommendation systems begin scaling.
| Common Mistake | Long-Term Problem |
|---|---|
| One centralized database | Creates scaling bottlenecks during viral traffic |
| Weak indexing strategy | Slows recommendation and feed retrieval |
| No caching layer | Increases latency and infrastructure load |
| Tight service coupling | Makes scaling difficult later |
| Direct synchronous writes | Overloads databases during engagement spikes |
Avoiding these mistakes early gives platforms significantly more long-term scalability flexibility.
How Miracuves Helps Businesses Build Scalable Video Platform Infrastructure
Miracuves helps businesses launch scalable TikTok-like ecosystems designed for engagement-heavy environments where millions of user interactions must be processed continuously in real time. Modern short-video platforms require much more than creator uploads and video playback. They also need infrastructure capable of supporting recommendation systems, distributed engagement processing, moderation workflows, analytics pipelines, feed personalization, and scalable event architecture.
The TikTok Clone Solution supports businesses planning scalable short-video ecosystems with architecture designed around recommendation responsiveness, engagement scalability, creator growth, and long-term operational stability. From feed systems and engagement tracking to scalable backend workflows, the infrastructure is built to support both early-stage launches and future traffic expansion.
As short-video ecosystems continue growing globally, scalable database infrastructure is becoming one of the most important systems behind recommendation quality, retention performance, creator engagement, and sustainable platform scalability. Businesses planning to launch scalable TikTok-like platforms can also contact the Miracuves team to discuss architecture planning, engagement scalability, and infrastructure requirements for high-growth video ecosystems.
Conclusion
Building scalable database architecture for modern video platforms requires much more than selecting between SQL and NoSQL systems. Successful short-video ecosystems depend on distributed infrastructure capable of handling massive engagement velocity, recommendation processing, indexing optimization, event pipelines, caching, and global scalability simultaneously.
As user-generated video ecosystems continue expanding globally, database performance increasingly affects recommendation quality, creator retention, monetization efficiency, and overall platform stability.
For businesses building TikTok-like platforms, scalable engagement architecture is rapidly becoming one of the most important long-term technical investments behind sustainable platform growth.
FAQs
Why do video platforms need distributed databases?
Distributed databases help video platforms handle massive engagement traffic, real-time feed updates, and global scalability without slowing recommendation systems.
What database is commonly used for engagement-heavy video apps?
Platforms often use PostgreSQL for structured data, Cassandra or DynamoDB for engagement events, and Redis for fast feed caching.
Why is sharding important in short-video platforms?
Sharding distributes traffic across multiple database nodes, helping platforms manage viral traffic spikes and large-scale engagement workloads efficiently.
How does indexing improve recommendation feed performance?
Efficient indexing helps recommendation systems retrieve personalized content faster, improving feed responsiveness and scrolling smoothness.
What happens when a viral video overloads a database?
Centralized databases may experience latency spikes, slow feed refreshes, overloaded analytics pipelines, and delayed engagement synchronization.
Why do TikTok-like apps use event pipelines?
Event pipelines help platforms process likes, comments, watch-time tracking, and recommendation signals asynchronously without overloading core databases.