




If you’re an entrepreneur or startup founder knee-deep in tech trends, you’ve probably had this moment: you’re using ChatGPT for text, Midjourney for images, and Whisper for speech-to-text—and you think, “Why isn’t this all in one place?” Ding ding ding. That’s where multimodal AI comes in—platforms that don’t just talk, but see, hear, and understand. It’s like Iron Man’s JARVIS—except instead of fighting crime, you’re helping creators, teams, and customers get stuff done at lightspeed.
But here’s the kicker: multimodal AI isn’t just a tech buzzword tossed around at AI conferences. It’s a goldmine in disguise. From AI tutors that analyze voice and handwriting to e-commerce assistants that recognize faces and tone, the demand is exploding. The real question is—how do you build a business model that doesn’t just work but wins?
If you’re looking to cash in on the multimodal revolution without getting tangled in technical spaghetti, this one’s for you. We’ll break down what works, what doesn’t, and how Miracuves can help you launch a revenue-ready AI platform faster than you can say “GPT who?”
What Is a Multimodal AI Platform?
Let’s decode the jargon: Multimodal AI platforms process multiple types of data—like text, images, audio, and video—simultaneously. Unlike traditional models that just “read” or “listen,” these platforms understand context across formats.
Think of it like this: a user uploads a voice note, an image of a receipt, and types a short caption. The AI interprets all three, makes sense of them together, and performs an action—say, generating an invoice. That’s not just smart—it’s next-gen productivity.
Real-World Use Cases
- Customer Support AI: Combines voice tone + chat + screen interactions.
- Healthcare Assistants: Analyzes patient voice, X-rays, and notes simultaneously.
- Content Creation: Merges voice prompts, image generation, and storyboarding.
Why Now? The Timing Is Perfect for Multimodal Platforms
Multimodal AI isn’t just a shiny toy anymore. It’s on the verge of mass adoption thanks to:
- Cloud computing + GPU boom: You can now train large models affordably.
- Device synergy: Smartphones, smartwatches, and smart assistants are everywhere—creating a sea of sensory data.
- Open-source catalysts: Tools like LLaVA, OpenAI’s GPT-4o, and Meta’s ImageBind make it easier to prototype.
Revenue Streams for Multimodal AI Platforms
Here’s the juicy bit: how do you turn this tech marvel into a profit machine? Let’s unpack the top monetization paths.
1. Freemium Model (With Usage Tiers)
Let people try it out—then charge for power. Example: 100 image/audio queries per month free; pay $19.99/month for 1000.
2. API-as-a-Service
Offer your AI as a plug-and-play API. Think Twilio for voice or Stability AI for image. Price it per call or per user.
- Ideal for: Startups, devs, SaaS tools that need image/audio/text magic.
3. Subscription SaaS
A flat monthly fee model for business teams. Use this if your platform targets:
- Marketing agencies
- Remote customer service
- Enterprise content teams
4. Pay-Per-Output
Each image, voiceover, or video costs credits. Popular in creative apps like Synthesia and Pika Labs.
5. Custom Model Licensing
Large corporations may want their own private AI clone. Offer “white-label” deployment with brand integration, custom training, and private hosting.
Must-Have Features of a Winning Multimodal AI App
To make money, you first need to make users stay. That means killer UX and smart feature design. Here’s what you need:
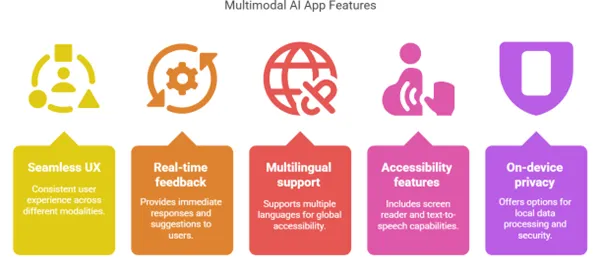
Seamless UX Across Modes
Users should switch from typing to speaking to uploading an image without friction.
Real-time Feedback
Don’t make them wait. Partial outputs, previews, and voice reads win hearts.
Localization & Accessibility
Include multilingual support, text-to-speech, and screen reader-friendly designs.
Data Privacy
Offer on-device processing or end-to-end encryption for sensitive tasks (think healthcare, finance).
Who Are You Competing With?
Here’s a quick peek at who’s playing in the multimodal arena:
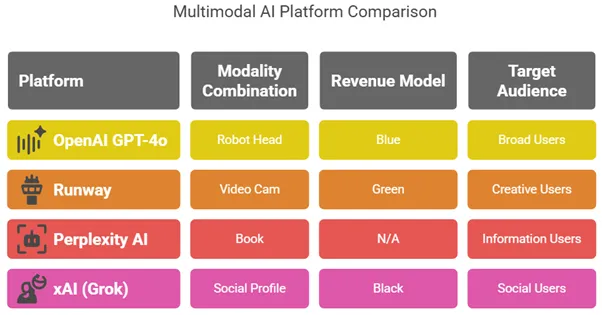
| Platform | Modality Combo | Revenue Model | Audience |
|---|---|---|---|
| OpenAI GPT-4o | Text + Image + Audio | API + ChatGPT Plus | Developers, Teams |
| Runway | Video + Image + Text | Pay-per-use | Creators, Filmmakers |
| Perplexity | Text + Image + Web | Freemium + Pro | Researchers |
| xAI (Grok) | Chat + Web | Twitter-native API? | X users |
You don’t need to be them—you just need to differentiate. Niche down. Be the best at one use case.
Read More : Pitfalls to Avoid When Building Your Own Google Gemini Clone
Scaling the Platform: Growth and Profit Strategies
Let’s get tactical. Once your platform is live, how do you grow it?
1. Creator Partnerships
Onboard creators early. Offer credits for every referred user or featured use case.
2. Developer Playground
Create a sandbox where developers can build tools using your API. Think “AI Lego kits.”
3. Marketplace Model
Let creators sell AI-generated assets—voice packs, prompt templates, avatar styles—and take a cut.
4. Reinforcement from Real Data
Use real-world inputs to fine-tune your model (with consent), improving performance and retention.
Challenges You’ll Need to Navigate
Even unicorns stub their toe. Here’s what could go wrong—and how to fix it.
- High Infra Costs: Offset with hybrid models (on-device + cloud) or use inference optimization tools.
- Content Moderation: Prevent misuse with watermarking, prompt validation, and human-in-the-loop moderation.
- Overchoice Paralysis: Don’t overwhelm users—suggest smart defaults and auto-format outputs.
Conclusion
Multimodal AI isn’t the future—it’s right now. And it’s moving faster than your inbox on a Monday morning. Whether you’re a creator tired of switching between tools, a founder looking for the next breakout platform, or an investor hunting scalable AI bets, this tech is the playground. It combines the power of language, vision, and audio into one seamless experience—and people are ready to pay for that magic.
At Miracuves, we help innovators launch high-performance app clones that are fast, scalable, and monetization-ready. Ready to turn your idea into reality? Let’s build together.
FAQs
1. What’s the difference between multimodal AI and traditional AI?
Traditional AI usually handles one type of data at a time (like text). Multimodal AI processes multiple types—like combining audio, image, and text—for richer, smarter responses.
2. How much does it cost to build a multimodal AI platform?
Depends on your scope. MVPs using open-source models can start at $20K–$50K. Full-scale platforms with APIs, real-time inference, and cloud hosting could go north of $200K.
3. Can I monetize just through ads?
You could, but ad models alone aren’t ideal for AI. Better to combine freemium, credits, and subscriptions for more sustainable revenue.
4. How do I protect user data?
Use end-to-end encryption, clear consent mechanisms, and optionally allow on-device processing for high-privacy scenarios like healthcare.
5. What’s the best niche to start with?
Start where complexity is high and current tools are fragmented—like voice note summarization, product explainer videos, or AI storytelling for kids.
Related Articles :




