Let’s face it—plain old text-based chatbots just don’t cut it anymore. In a world where your fridge can talk back, and your phone knows more about you than your best friend, users expect more. In 2025, the conversation isn’t just about chatbots—it’s about creating experiences. And that means going beyond text. That means multimodal AI chatbots: ones that can handle voice, text, images, videos, and even real-time sentiment. These platforms aren’t just a nice-to-have anymore—they’re your ticket to staying relevant.
Back in 2020, I built my first chatbot using a drag-and-drop interface. It was clunky. It could only spit out canned responses. And sure, it worked—for a bit. But once users wanted to upload a picture, speak a question, or get a video answer, the limitations screamed. That’s when I knew: the future of human-computer interaction isn’t one-dimensional. It’s all about multimodal inputs and outputs. Whether you’re building for e-commerce, healthcare, edtech, or just want a smarter customer assistant, you’ve got to up your game.
In this blog, we’re diving into the how-to of it all. You’ll discover what goes into building a full-fledged multimodal AI chatbot—from choosing the right tech stack and training data, to integrating voice recognition, image processing, and NLP models. We’ll also touch on monetization (yep, this isn’t just for fun), creator tools, and platform scalability.
So buckle up. If you’re an entrepreneur, a startup founder, or even a curious product manager eyeing the next big thing in AI—this guide’s for you. Let’s build something that doesn’t just chat. Let’s build something that talks, listens, sees, thinks—and gets smarter with every interaction.
What Is a Multimodal AI Chatbot?
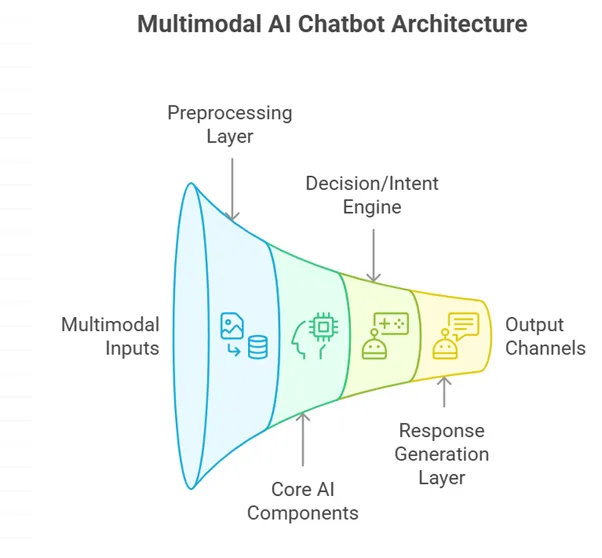
A multimodal AI chatbot is an advanced conversational agent capable of understanding and generating responses using multiple data types: text, voice, image, video, and even sensor input. Think of it as a brain with five senses instead of one.
- Text-based chat? Check.
- Voice commands and speech replies? Double check.
- Visual recognition via uploaded images or live camera feed? Absolutely.
- Real-time emotion analysis from tone or facial expressions? Getting there.
By blending natural language processing (NLP), computer vision (CV), and automatic speech recognition (ASR), multimodal bots offer human-like conversations—minus the awkward small talk.
Why Build One Now?
- User demand for immersive interactions is booming.
- Generative AI has made multi-input models more accessible.
- Industries like healthcare, finance, and e-commerce are craving contextual, accurate bots.
- ChatGPT, Gemini, and Meta’s LLaMA models have raised the bar—your users expect better.
Components of a Multimodal AI Platform
Let’s break down what goes into building this AI beast.
1. NLP Engine
- Purpose: Understand and generate natural language text.
- Tools: OpenAI GPT, Google Gemini, Cohere, LLaMA.
- Key Feature: Context retention, multilingual capabilities.
2. Speech-to-Text (ASR)
- Purpose: Convert voice input to text.
- Tools: Whisper by OpenAI, Google Speech API, Deepgram.
- Consideration: Must handle noisy environments and accents.
3. Text-to-Speech (TTS)
- Purpose: Convert AI response into human-like speech.
- Tools: Amazon Polly, Google WaveNet.
- Advanced Tip: Use voice cloning for branded bots.
4. Computer Vision Layer
- Purpose: Analyze images, gestures, or visual inputs.
- Tools: OpenCV, YOLO, CLIP, Detectron2.
- Bonus Use Cases: OCR, object detection, face recognition.
5. Knowledge Base / LLM Integration
- Purpose: Access context, historical data, or industry-specific knowledge.
- Tools: LangChain, RAG pipelines, Vector databases (FAISS, Pinecone).
6. Multimodal Fusion & Context Manager
- Purpose: Blend inputs (text+image, voice+video) into a coherent understanding.
- Advanced Feature: Dialogue management based on sensory priorities.
Development Workflow
Step-by-Step Blueprint
- Define Your Use Case
Healthcare? Retail? Edtech? Each domain needs unique training data. - Choose the Right Model Architecture
- Encoder-Decoder for input/output pairing.
- Transformers for sequence modeling.
- Vision-language models for visual tasks.
- Collect & Curate Training Data
- Multimodal datasets: MSCOCO, AVSD, VQA, Flickr8k.
- Include real-world noise: slang, blurry photos, voice cracks.
- Design UI/UX for Multimodal Interaction
Think touch buttons + mic icons + image upload + text box. Simplicity wins. - Integrate APIs & Pipelines
- Use WebSockets for real-time audio.
- REST for image-based tasks.
- Use LLM wrappers (LangChain or Haystack) for advanced orchestration.
- Test and Iterate
Include edge cases, stress test modalities, simulate high-traffic interactions.
Choosing the Right Stack for Your Goals
| Platform Use Case | Best Stack Combination |
|---|---|
| Healthcare Assistant | Whisper + GPT-4 + MedPaLM + OpenCV |
| Retail Bot | Google ASR + Gemini + Visual Search + Stripe Integration |
| EdTech Guide | Speech APIs + LLaMA + Hugging Face Transformers + CLIP |
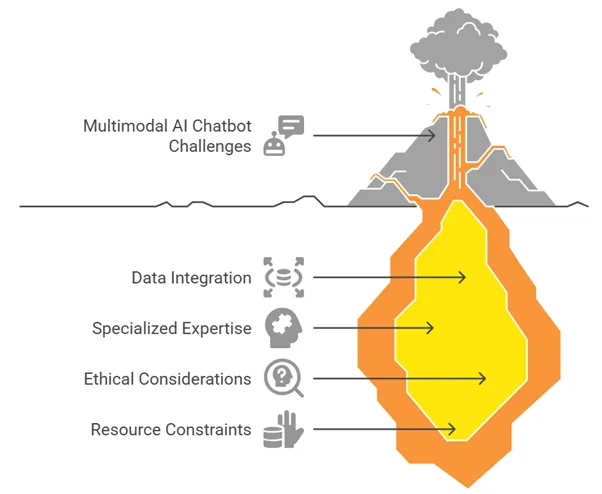
Common Challenges and Pitfalls
Data Conflicts
Multimodal inputs may contradict each other. Imagine a user says “no” while nodding “yes.” Your system needs to prioritize or flag for human review.
Cost & Latency
Processing voice, video, and vision in real time eats up GPU and money. Use asynchronous loading and response prioritization.
Privacy Concerns
Voice and image input = biometric data. Ensure GDPR compliance, anonymization, and opt-out features.
Conclusion
Chatbots have been quite helpful and with the future trend it looks to bring :
- Emotionally intelligent bots that can detect sentiment from tone + expression.
- Haptic feedback for physical interactions.
- Multilingual multimodality: Speak Hindi, upload English image, get Telugu reply.
- Edge computing to reduce latency in AR/VR use cases.
FAQ
1. What makes a chatbot “multimodal”?
It can process and respond using more than one mode of input/output—like voice + text or image + video.
2. Is it expensive to build?
Not if you’re smart with open-source tools. Hosting and GPU usage can scale with traffic. Start small, scale gradually.
3. Can I integrate this with my website?
Yes! Use React or Vue.js front-ends with WebSocket or REST APIs. Also integrates with platforms like WhatsApp, Slack, and even kiosks.
4. What industries benefit most?
Healthcare, education, banking, e-commerce, and entertainment are leading the adoption race.
5. Do I need a team of AI experts?
Not necessarily. You can use pre-trained APIs, fine-tune LLMs, and work with low-code AI tools for prototyping.