Key Takeaways
- Super apps face multiple traffic patterns at once.
- A 300% traffic spike can expose weak architecture.
- Database isolation helps contain service failures.
- Food and ride modules should scale independently.
- Reliability matters more than feature count.
Architecture Signals
- Separate food delivery and ride-hailing data pools.
- Protect checkout and booking transaction paths.
- Use queues for notifications and background tasks.
- Keep reporting away from live transaction databases.
- Monitor latency, load, and service health continuously.
Real Insights
- Shared databases often fail during peak demand.
- One overloaded service should not affect others.
- Traffic spikes are operational challenges, not feature issues.
- Scalability decisions should happen before launch.
- A super app succeeds when load is isolated and controlled.
A Gojek-style super app looks simple from the outside. One app. Multiple services. A user books a ride, orders food, sends a parcel, pays digitally, and tracks everything from a single interface.
But from an engineering perspective, a multi-service platform is not one app. It is several high-pressure businesses sharing the same digital surface.
Ride-hailing creates real-time matching pressure. Food delivery creates checkout, menu, merchant, kitchen, and delivery allocation pressure. Courier delivery creates tracking and proof-of-delivery pressure. Wallets and payments create transaction consistency pressure. The founder sees one product. The backend sees several different demand patterns fighting for infrastructure at the same time.
That difference matters.
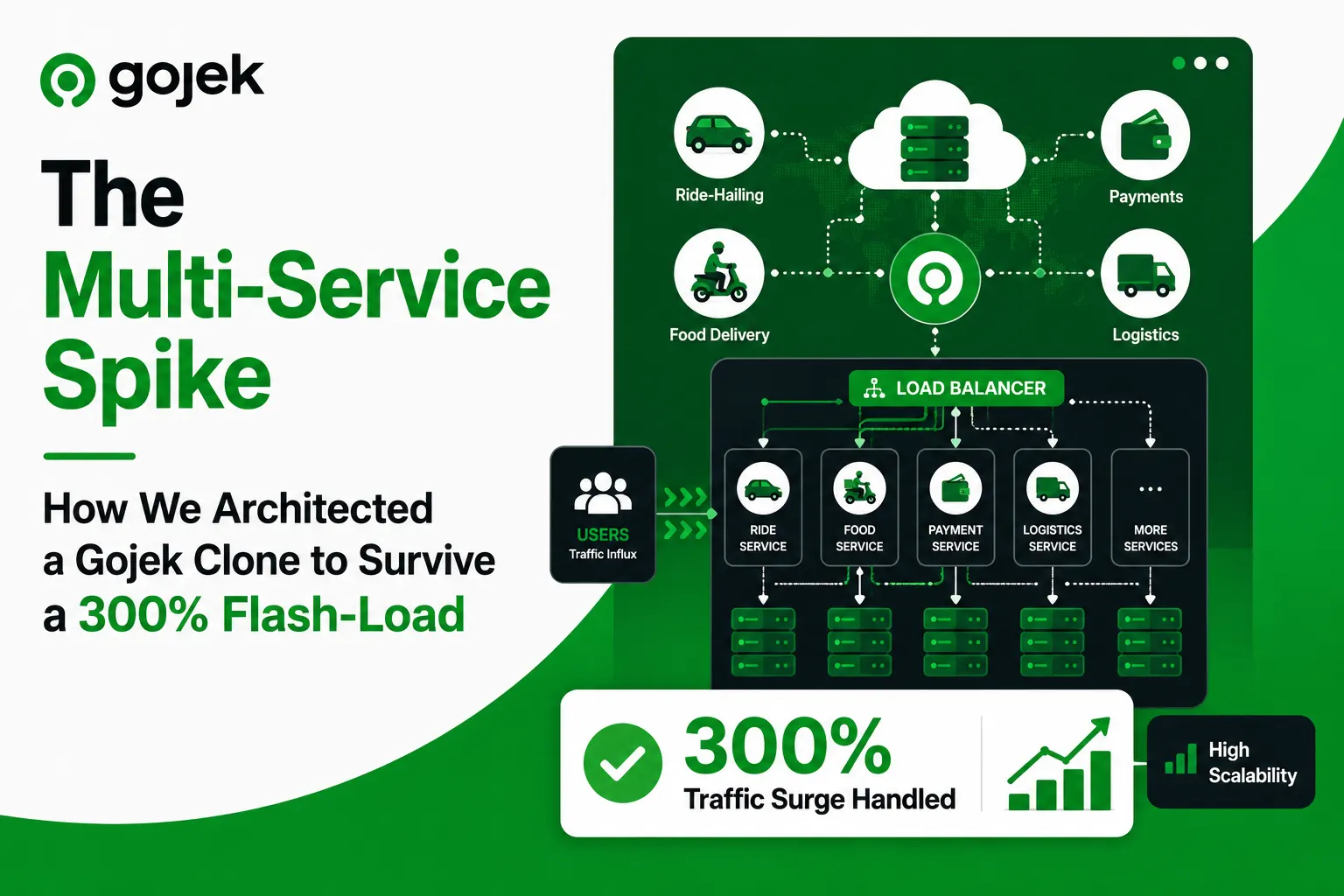
In one Gojek-style deployment, the platform experienced a sudden 300% increase in concurrent food and ride requests. The spike could have taken down the entire ecosystem if both verticals were dependent on the same shared database pool. Instead, the architecture isolated the data engines for food delivery and ride-hailing, keeping the overload contained and preventing a full system crash.
This case study explains the database engineering choices behind that result, why generic unoptimized scripts collapse under this kind of load, and what founders should evaluate before launching a multi-service super app.
Why Super-App Reliability Is Harder Than Launching Multiple Services
Many founders think the hard part of a super app is adding more modules.
Ride-hailing. Food delivery. Grocery. Courier. Home services. Payments. Provider dashboards. Merchant dashboards. Driver apps. Admin controls.
Those modules matter, but they are not the real operational challenge. The deeper challenge is making sure these services do not damage each other when demand spikes.
A food delivery rush does not behave like a ride-hailing rush. A ride-hailing surge is location-heavy, matching-heavy, and time-sensitive. A food delivery surge is catalogue-heavy, cart-heavy, order-heavy, merchant-heavy, and delivery-allocation-heavy. Both can happen at the same time, especially during festivals, office lunch windows, rainfall, sports events, concerts, or regional promotions.
When the platform is small, shared infrastructure may appear acceptable. The database responds fast enough. The admin dashboard works. Drivers receive requests. Restaurants accept orders. Users do not notice the risk.
The risk appears when demand concentrates suddenly.
A 300% spike in concurrent ride and food requests does not only mean more users. It means more reads, more writes, more locks, more payment attempts, more dispatch events, more notifications, more location updates, more retries, and more admin visibility requests. If every vertical depends on the same overloaded database layer, one service can drag the others down.
For entrepreneurs and regional enterprise investors, this is the difference between launching a super app and operating one.
Read more: What is Gojek App and How Does It Work?
The Multi-Vendor Nightmare: Why Shared Databases Fail at Peak Hours

A generic multi-service script often starts with a convenient assumption: keep services together, reuse the same database, and separate the experience at the UI level.
That can work for demos. It can even work for early validation. But peak-hour traffic exposes the weakness.
Imagine this sequence.
A food campaign goes live at 7:30 PM. Thousands of users open restaurant menus, apply coupons, add items to cart, check delivery fees, and place orders. At the same time, rain increases ride demand across the city. Drivers are receiving ride requests, rejecting some, accepting others, and updating their locations every few seconds.
Now the database is handling:
- Restaurant menu reads
- Cart updates
- Coupon validation
- Order creation
- Payment status updates
- Driver location writes
- Ride matching reads
- Fare recalculation
- Delivery assignment
- Admin dashboard queries
- Notification event logs
- Customer support lookups
If all these workloads use the same connection pool and compete against the same database resources, the system starts to show stress in predictable ways.
Cart updates slow down. Ride matching takes longer. Payment callbacks wait behind non-critical reads. Admin dashboards become unreliable. Some users retry the same action, creating even more pressure. The platform does not fail because one feature is broken. It fails because unrelated workloads are allowed to compete without boundaries.
This is the multi-vendor nightmare.
The food vertical, ride vertical, courier vertical, merchant workflows, driver workflows, and admin workflows all look connected from a business perspective. But from a database engineering perspective, they need controlled separation.
Isolating the Engines: Food Delivery vs. Ride-Hailing Data Pools
The architecture decision that protected the platform during the 300% spike was not cosmetic. It was structural.
Instead of forcing all service modules into one shared database pressure zone, the backend separated critical data pools by service behavior.
Food delivery had its own database pool for high-frequency order, cart, restaurant, menu, and delivery assignment operations. Ride-hailing had a separate pool for booking, driver availability, ride matching, location state, and trip updates. Shared identity, wallet, support, and admin data were handled with controlled access patterns instead of uncontrolled cross-service dependency.
This created a simple but powerful outcome: a spike in one vertical did not automatically exhaust the database capacity of the other.

Food Delivery Data Pool
Food delivery traffic is usually bursty around predictable windows. Lunch, dinner, weekends, local campaigns, and weather events can produce sudden read/write pressure.
The food delivery pool was optimized around:
- Restaurant and menu reads
- Cart state updates
- Coupon and pricing validation
- Order placement
- Merchant order acceptance
- Delivery partner assignment
- Order status progression
- Refund and cancellation records
The key engineering priority was protecting checkout and order creation from being blocked by less critical operations. Menu browsing and search can tolerate some caching and delayed freshness. Payment confirmation and order creation cannot.
Ride-Hailing Data Pool
Ride-hailing traffic behaves differently. It is location-sensitive, matching-sensitive, and latency-sensitive.
The ride-hailing pool was optimized around:
- Rider booking requests
- Driver availability
- Geo-based matching
- Trip status updates
- Fare and route metadata
- Cancellation events
- Driver acceptance and rejection flows
- Live trip records
The priority was keeping the matching and trip-state path responsive. A ride request that arrives late is not only a slow database event. It can become a lost booking, a frustrated driver, and a poor user experience.
Shared Services Without Shared Failure
Some services still need to communicate across the ecosystem. Users, wallets, payments, notifications, support tickets, commissions, and admin reporting often span multiple verticals.
The goal is not to isolate everything blindly. The goal is to define which systems need strong consistency, which can work asynchronously, and which should not sit directly in the critical booking path.
For example, analytics does not need to block order placement. Promotional reporting does not need to block ride matching. Admin summaries do not need to run heavy queries against live transactional tables during peak demand. When those boundaries are respected, the platform becomes more resilient.
Database Isolation Decisions for a Gojek-Style Super App
| System Area | Primary Load Pattern | Database Engineering Choice | Business Impact |
|---|---|---|---|
| Food Delivery | Cart updates, checkout, merchant acceptance, delivery assignment | Separate food delivery pool with protected order-write path | Prevents food-order traffic from blocking ride requests during dinner or campaign spikes |
| Ride-Hailing | Driver matching, location updates, trip state changes | Separate ride pool optimized for real-time booking and matching state | Keeps ride matching responsive even when food delivery traffic surges |
| Wallet and Payments | Payment callbacks, wallet debits, refunds, settlement records | Controlled transactional flow with retry-safe processing | Reduces payment inconsistency and protects revenue-critical events |
| Admin Dashboard | Reports, search, operational monitoring, dispute lookup | Read-optimized access and separation from critical live transactions | Allows operators to monitor the business without slowing customer actions |
| Notifications and Events | Push notifications, status updates, email/SMS triggers | Queue-based processing where real-time blocking is not required | Prevents notification delays from affecting bookings or orders |
Real-World Latency Drops Under Stress
The most important metric in this deployment was not that traffic increased. It was that failure did not spread.
During the flash-load event, concurrent food and ride requests rose by 300% over the normal operating baseline. In a shared-pool architecture, this would typically create connection exhaustion, slow queries, queue pileups, and cross-service degradation. The user placing a food order and the user booking a ride would both suffer, even though their workflows are different.
With isolated database pools, the platform behaved differently.
The food delivery spike increased pressure on food-specific tables, checkout flows, merchant acceptance, and delivery allocation. Ride-hailing continued operating through a separate pool built around matching, driver availability, trip state, and location-sensitive reads. Instead of one platform-wide slowdown, the architecture allowed each service engine to absorb pressure independently.

That is the real value of database partitioning in a super app.
It does not magically remove load. It organizes load so the business can survive it.
When latency did rise in one vertical, the effect was contained. Food-specific pressure did not automatically slow ride matching. Ride-side pressure did not block food checkout. Admin visibility remained usable because reporting and operational queries were not allowed to compete directly with the highest-priority transaction paths.
For founders, this matters because super-app users do not care which internal module failed. If they cannot book, order, pay, or track, they blame the whole platform.
Read more: Best Gojek Clone Script in 2026: Features & Pricing Compared
What Generic Gojek Clone Scripts Usually Get Wrong
Generic scripts often look attractive because they promise many services in one package. The screenshots look complete. The modules look broad. The admin panel looks busy. The demo may include ride-hailing, food delivery, grocery, courier, home services, wallets, and commissions.
But reliability is not visible in a demo.
The risk appears when the platform handles real concurrency. Many generic scripts fail because they are optimized for feature count instead of workload separation.
Common problems include:
- One shared database pool for unrelated service workloads
- No clear separation between food, ride, courier, wallet, and admin pressure
- Heavy admin reports running on live transactional tables
- Weak caching for high-read modules like menus and service listings
- Poor retry logic for payment and notification events
- No queue strategy for non-blocking workflows
- Lack of service-level rate limits
- No clear distinction between critical and non-critical queries
- Limited observability into which vertical is causing load
- Scaling infrastructure only after failure has already happened
A multi-service app does not collapse only because it lacks servers. It collapses because the architecture does not know which traffic deserves priority.
If every query is treated equally, the checkout path can lose to a report query. If every service shares the same pool, ride matching can suffer because food users are browsing menus. If every event is synchronous, notification delays can slow down transaction completion.
That is why serious super-app architecture needs operational discipline before aggressive expansion.
Founder Decision Signals Before Launching a Super App
Founder Decision Signals
Speed
A ready-made super-app foundation can help you launch faster, but speed should not come at the cost of database reliability. Ask whether each core vertical can be scaled or isolated independently.
Cost
The cheapest-looking script can become expensive if it needs emergency re-engineering after peak traffic. Evaluate architecture quality before comparing only upfront development cost.
Scalability
A scalable Gojek clone architecture should separate food, ride, courier, wallet, and admin pressure instead of forcing every service into the same backend bottleneck.
Market Fit
If your market has predictable rush hours, festival demand, weather-driven ride spikes, or campaign-led food orders, your first launch version should already account for flash-load behavior.
Before choosing a super-app development partner, founders should ask practical engineering questions:
- Can the food delivery module scale separately from ride-hailing?
- Can admin reporting be separated from live transaction paths?
- Can payment callbacks be retried safely without duplicate orders or wallet confusion?
- Can the platform identify which service is causing stress during peak load?
- Can low-priority workloads be throttled while bookings and checkout remain protected?
- Can new services be added without increasing the failure risk of existing services?
These questions are more useful than asking only how many modules the app includes.
A super app with 50 poorly isolated modules is weaker than a platform with fewer services and stronger operational control.
How Miracuves Builds Reliability Into Multi-Service Rollouts
Miracuves helps founders and regional enterprise teams launch ready-made, white-label, source-code-owned app platforms with business model clarity and admin control. For a Gojek-style super app, that means the product conversation should not stop at features.
It should include architecture.
A multi-service rollout needs customer apps, provider apps, merchant workflows, driver workflows, service management, commissions, payments, tracking, notifications, and admin dashboards. But it also needs a backend foundation that understands how each vertical behaves under pressure.
For founders planning a Gojek clone app, the stronger approach is to begin with a launch-ready foundation and customize it around operational realities: geography, service mix, traffic pattern, payment methods, driver supply, merchant density, and expected campaign behavior.
A food-first super app needs a different stress plan than a ride-first super app. A city-wide delivery marketplace needs different partitioning logic than a regional enterprise platform with multiple service categories. A platform that expects corporate bookings, scheduled services, or wallet-heavy usage needs stronger transaction and admin workflows from the beginning.
Miracuves’ white-label super-app approach gives founders a faster foundation while still allowing the architecture to be adapted around service priorities, admin controls, and scalability requirements.
Read more: Gojek App Marketing Strategy: How this Became as Super App
Mistakes Founders Should Avoid
Mistakes Founders Should Avoid
Choosing a super-app script only by feature count
A long feature list does not prove the backend can survive peak load. Founders should evaluate database separation, service-level scaling, admin reporting behavior, and payment reliability before choosing a vendor.
Letting admin dashboards compete with live transactions
Operational reporting is useful, but heavy dashboard queries should not slow down ride booking, food checkout, or payment confirmation during peak traffic.
Scaling only after the first crash
Once users experience failed orders or delayed rides, trust is already damaged. Super-app platforms should be load-tested before launch, especially around service combinations that are likely to spike together.
Treating food delivery and ride-hailing as the same workload
Food delivery is order, catalogue, merchant, and delivery-assignment heavy. Ride-hailing is matching, location, and trip-state heavy. These workloads need different database and backend priorities.
Final Thoughts:
The real challenge in Gojek clone architecture is not adding more services into one product. It is preventing one service from damaging the others when traffic becomes unpredictable.
A 300% spike in concurrent food and ride requests is exactly the kind of event that exposes weak architecture. If the food delivery engine, ride-hailing engine, payment layer, admin dashboard, and notification system all depend on the same overloaded database resources, the platform becomes fragile.
Database partitioning, isolated service pools, queue-based workflows, and critical-path protection turn a super app from a feature bundle into an operating system for regional demand.
For founders and enterprise investors, the question is not simply, “Can we launch a Gojek clone?”
The better question is, “Can our platform survive the moment users actually start depending on it?”
Miracuves helps founders move from idea to launch faster with ready-made, white-label, source-code-owned app solutions designed for branding, admin control, monetization, and scalable operational planning.
Ready to build a scalable Gojek clone that can handle real-world demand? Contact us today to discuss your super app idea, feature requirements, and launch roadmap.
FAQs
What is Gojek clone architecture?
Gojek clone architecture refers to the backend, database, app, admin, and service-module structure behind a multi-service platform inspired by Gojek. A strong architecture supports ride-hailing, food delivery, courier, grocery, payments, provider dashboards, merchant flows, and admin controls while keeping critical services scalable and reliable.
Why do generic Gojek clone scripts fail during peak traffic?
Generic scripts often fail because they focus on feature count rather than workload separation. If ride-hailing, food delivery, courier, wallet, and admin queries all share the same overloaded database pool, one service spike can slow down the entire platform.
How does database partitioning help a super app?
Database partitioning helps separate service workloads so that each vertical can handle pressure more independently. In a Gojek-style platform, food delivery and ride-hailing can use different database pools, reducing the chance that one overloaded service crashes the whole ecosystem.
Should food delivery and ride-hailing use the same database?
They can share some common systems, such as user identity or wallet records, but their high-pressure transactional workloads should be carefully separated. Food delivery creates cart, order, menu, merchant, and delivery allocation pressure, while ride-hailing creates matching, location, and trip-state pressure.
What should founders check before buying a Gojek clone app?
Founders should check whether the platform supports modular services, source-code ownership, admin control, service-level scaling, payment reliability, database isolation, monitoring, and load testing. The goal is not only to launch quickly but to operate reliably during real demand.
Can a ready-made Gojek clone be scalable?
Yes, a ready-made Gojek clone can be scalable if the architecture supports modular services, database separation, cloud deployment planning, optimized queries, queue-based processing, and admin controls. Scalability depends on the engineering foundation, not only the label “ready-made.”
How does Miracuves support super-app development?
Miracuves helps founders build ready-made and white-label super-app solutions with source code, custom branding, admin dashboards, multi-service modules, and faster deployment. The platform can be adapted around the business model, regional operations, and service mix.
Is a Gojek clone suitable for regional enterprise investors?
Yes, a Gojek-style super app can be suitable for regional enterprise investors when there is demand for multiple on-demand services in one market. The key is to validate service priority, operational density, supply-side availability, payment readiness, and backend scalability before expanding too quickly.