Key Takeaways
- A reliable AI app should not depend on a single model provider for every user request.
- Multi-model fallback architecture can route traffic between OpenAI, Claude, Gemini, and other approved models.
- Health checks, timeout rules, routing policies, retries, and observability are core resilience layers.
- Fallback decisions should consider response quality, latency, cost, availability, and task suitability.
- A provider-independent AI architecture can reduce disruption and protect the user experience during service failures.
Architecture Signals
- Users need fast, accurate, and consistent responses even when a preferred model becomes unavailable.
- AI routing systems need provider health checks, latency thresholds, retry limits, and task-specific model selection.
- Admins need control over model priorities, usage limits, fallback rules, API credentials, costs, and reports.
- Prompt normalization and standardized outputs help maintain consistency when requests move between models.
- Real-time alerts help teams detect rate limits, elevated latency, failed requests, cost spikes, and provider outages.
Real Insights
- An AI product becomes fragile when one external API controls its entire customer experience.
- Fallback models should be tested for each task instead of being treated as automatically interchangeable.
- Uncontrolled retries can increase response time and API costs without improving completion rates.
- Provider abstraction, evaluation datasets, audit logs, and cost-aware routing improve long-term platform control.
- Miracuves builds AI apps with multi-model routing, automated fallbacks, usage monitoring, and admin-controlled provider workflows.
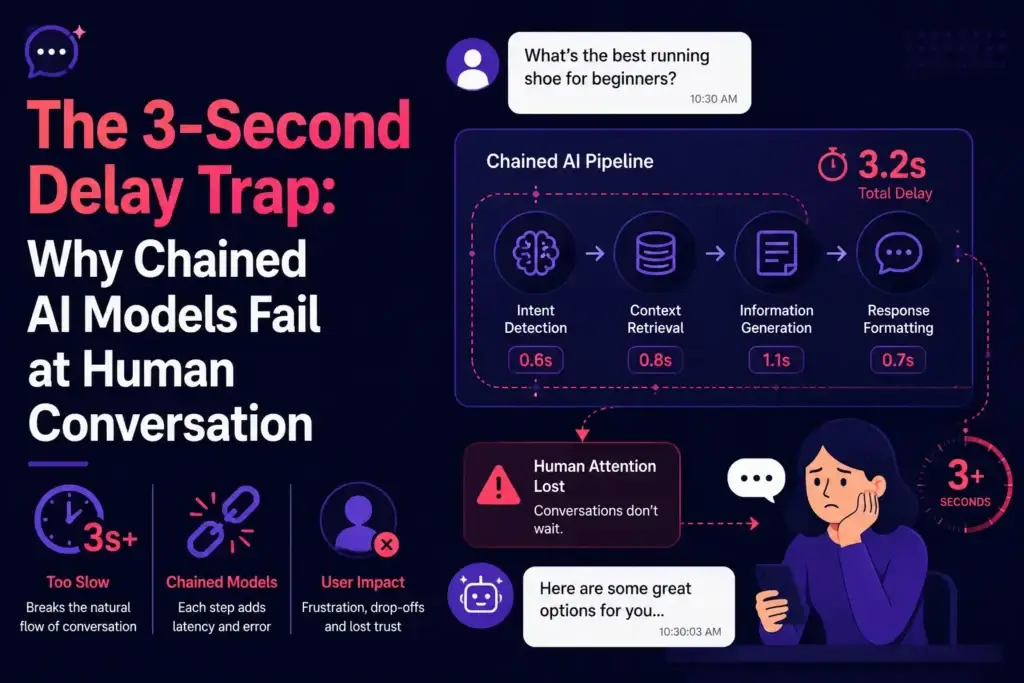
A polished interface can make a ChatGPT-like platform look complete, but visual quality alone does not make an AI product reliable.
The real test begins when the primary model provider slows down, rejects requests, reaches a rate limit, or becomes temporarily unavailable. A basic AI wrapper sends every prompt to one external API. When that dependency fails, the application fails with it.
An enterprise-ready AI app requires a different architecture. Instead of connecting the user interface directly to one model, the application places an orchestration layer between the product and its model providers. That layer evaluates availability, latency, model capability, cost, and request type before choosing where each prompt should go.
This case study explains the architecture Miracuves uses as a foundation for resilient, white-label AI applications. Its broader AI and automation solutions approach supports multi-model routing that can move requests between OpenAI, Anthropic Claude, Gemini, or another approved provider whenever the primary route cannot meet the required service threshold.
The Single-API Dependency Trap: Why Basic AI Wrappers Crash
A thin AI wrapper normally follows a simple request path:
User interface → application backend → one model API → response
This approach is fast to prototype. It is also structurally fragile.
The application may have its own servers, database, authentication system, billing layer, and admin dashboard working normally. However, if the single model API is unavailable, the product’s core function stops.
Rate limits are one obvious failure condition. OpenAI describes rate limits as restrictions on how frequently a client can access its API, and its documentation shows that requests can return errors when usage exceeds the allowed request rate.
Production failures can also include:
- Connection timeouts
- Elevated response latency
- HTTP 429 rate-limit responses
- Temporary 5xx provider errors
- Regional network issues
- Model-specific capacity constraints
- Authentication or quota configuration errors
- Streaming interruptions
- Safety or policy-related rejections
- Provider maintenance or service incidents
A basic wrapper often treats these outcomes in one of two ways. It either displays a generic error to the user or repeatedly sends the same request to the same failing provider.
Neither response creates resilience.
Repeated retries can make congestion worse. Immediate errors protect infrastructure but damage the user experience. The better approach is to classify the failure and decide whether the system should retry, delay, downgrade, or route the prompt elsewhere.
Read More: What is ChatGPT App and How Does It Work?
Why Interface Quality Is Not the Same as Product Reliability

Two AI apps may have nearly identical interfaces while behaving very differently under production load.
The first app may send every prompt directly to a single model. The second may use an abstraction layer with multiple providers, configurable routing policies, health monitoring, token controls, and an audit trail.
The difference is largely invisible during a normal demo.
It becomes obvious during an incident.
| Architecture layer | Thin AI wrapper | Resilient multi-model app |
|---|---|---|
| Model dependency | One provider | Multiple approved providers |
| Error handling | Generic retry or failure | Error classification and policy-based routing |
| Latency control | Wait for primary provider | Route when thresholds are exceeded |
| Context handling | Provider-specific format | Normalized internal message format |
| Monitoring | Basic application logs | Provider, model, latency, token, error, and fallback telemetry |
| Admin control | Limited | Routing rules, provider status, limits, and manual overrides |
| User experience | Visible interruption | Continuity where fallback is safe |
| Business risk | Concentrated | Distributed and controlled |
This is why selecting an AI app based only on its visible features is risky. A buyer must understand how the backend behaves when dependencies do not perform as expected.
Read More: How AI Chat Platforms Make Money
The Architecture Behind Multi-Model Fallback Routing

The multi-model design separates the product experience from the model provider.
Instead of letting the frontend call OpenAI, Claude, or Gemini directly, every prompt enters a central orchestration service.
A simplified request path looks like this:
User → API gateway → authentication and quota checks → prompt policy layer → model router → selected provider → response normalizer → user
The router is responsible for deciding which provider should process the request. It uses current health data and predefined business rules rather than hard-coding every prompt to one model.
1. A Provider-Neutral Request Format
OpenAI, Anthropic, and Google do not necessarily represent messages, tools, system instructions, streaming events, and token usage in exactly the same way.
The application therefore converts incoming conversations into an internal format before choosing a provider.
That normalized object may contain:
- System instruction
- Conversation history
- Current user prompt
- Required tools
- Response format
- Safety classification
- Maximum token budget
- Latency target
- Preferred model tier
- Fallback permissions
- Data-handling restrictions
Provider adapters then translate this internal object into the format expected by the selected API.
This prevents the rest of the product from becoming tightly coupled to one vendor’s request schema.
2. A Routing Policy Rather Than a Hard-Coded Provider
The primary provider can still receive most traffic. The difference is that it is selected through a routing policy.
A policy might say:
- Send general conversations to the primary model.
- Retry once when a transient network failure occurs.
- Route to the secondary provider after a retryable 5xx response.
- Route immediately after an eligible rate-limit response.
- Use a faster fallback when latency crosses the approved threshold.
- Do not reroute requests involving unsupported tools or restricted data.
- Preserve the original provider for workflows requiring exact model continuity.
- Stop after the defined fallback chain is exhausted.
This gives the platform operator control over resilience, cost, quality, and compliance.
3. Live Health and Latency Signals
A reliable router should not wait for every user request to fail before recognizing that a provider is unhealthy.
It can maintain a rolling view of:
- Success rate
- Timeout rate
- Rate-limit frequency
- P50, P95, and P99 latency
- Streaming interruption rate
- Provider-specific error codes
- Token throughput
- Cost per successful request
- Fallback frequency
- Recovery status
A circuit breaker can temporarily stop sending traffic to a provider when failures cross a defined threshold. After a cooling period, the system can send controlled probe requests before restoring normal traffic.
This protects users from repeatedly hitting a known failure condition.
Read More: How Safe is a White-Label ChatGPT App? Security Guide 2026
Engineering Seamless Fallbacks Between GPT and Claude
Moving a prompt from one provider to another sounds simple until the application must preserve the user’s conversation, tools, output format, safety rules, and billing record.
A proper fallback sequence involves more than changing an endpoint.
Step 1: Classify the Failure
The router first determines whether the failure is eligible for fallback.
A timeout, temporary server error, or rate-limit response may justify another route. An invalid API credential does not. A malformed request should be corrected rather than sent elsewhere. A safety refusal should not automatically be bypassed through a different provider.
This distinction is essential. Otherwise, fallback logic can become an uncontrolled retry loop or a mechanism that circumvents product policies.
Step 2: Check Whether the Request Is Portable
Not every prompt can be transferred safely between models.
A standard text conversation is comparatively portable. A request involving provider-specific tools, structured outputs, proprietary fine-tuning, cached context, vision inputs, or a particular moderation policy may require additional handling.
The router checks the request against a capability matrix before selecting a fallback.
| Requirement | Primary route | Fallback condition |
|---|---|---|
| General text conversation | Preferred general model | Any approved general model |
| Structured JSON | Model supporting schema controls | Fallback must support validated structured output |
| Tool calling | Provider with required tool support | Adapter must map tool definitions and results |
| Image understanding | Multimodal model | Secondary model must accept the same input type |
| Sensitive workflow | Approved deployment route | No fallback outside approved data boundary |
| Long conversation | Large-context model | Fallback must support the required context length |
Step 3: Preserve Conversation State
The orchestration layer retrieves the relevant conversation history and converts it into the fallback provider’s expected structure.
It also applies token-budget controls. A conversation that fits one model’s context window may need summarization or selective memory retrieval before it can be moved to another model.
The user should not have to restart the conversation simply because the underlying provider changed.
Step 4: Apply the Same Product Policies
A fallback response must still follow the application’s rules.
That includes:
- System prompts
- Brand tone
- Restricted-topic policies
- Retrieval permissions
- Tool access
- Output formatting
- Data-retention settings
- User plan limits
- Moderation requirements
Without a centralized policy layer, two providers may produce inconsistent experiences even when both are technically available.
Step 5: Record the Failover Event
Every failover should create an observable event.
The system should record:
- Original provider
- Original model
- Failure category
- Retry count
- Fallback provider
- Fallback model
- Routing reason
- End-to-end latency
- Token consumption
- Request cost
- Final outcome
- Whether the user saw an interruption
This data allows the engineering team to distinguish a successful resilience strategy from one that merely hides recurring infrastructure problems.
Read More: Best ChatGPT Clone Script in 2026: Features & Pricing Compared
How Latency-Based Routing Works
Not every provider problem appears as a complete outage. Sometimes the API continues responding but takes too long to meet the product’s user-experience target.
Latency-aware routing addresses this grey area.
Suppose the platform’s routing policy establishes:
- A normal primary-provider latency range
- A warning threshold
- A hard timeout
- A minimum sample size
- A cooldown period
- A secondary-provider health requirement
When rolling latency moves beyond the warning threshold, the router can reduce the percentage of new requests sent to the primary route. If the hard threshold is crossed, eligible requests move to the fallback provider.
The transition may use:
- Immediate failover: All eligible requests switch after a critical condition.
- Weighted routing: Traffic gradually moves from one provider to another.
- Hedged requests: A secondary request starts after a delay, and the first valid response wins.
- Capability-based routing: Requests move according to model strengths rather than provider health alone.
Hedged requests can reduce tail latency but may increase cost because more than one provider can process the same prompt. They should therefore be used selectively.
Read More: Business Model of ChatGPT 2026
Why “The User Never Notices” Needs Careful Engineering
A seamless fallback does not mean that every response from every model is identical.
Different models may vary in:
- Tone
- Reasoning style
- Refusal behaviour
- Tool-call formatting
- Citation format
- Response length
- Structured-output reliability
- Tokenization
- Latency
- Cost
The goal is not to pretend that the providers are interchangeable. The goal is to keep the product functional while preserving an acceptable quality standard.
Miracuves’ routing approach can reduce visible disruption by standardizing system instructions, response formatting, conversation state, and application-level policies. However, the platform should still test fallback quality against real task categories before enabling automatic switching in production.
For enterprise workflows, fallback may be restricted to model pairs that have passed scenario-based evaluation.
The 99.99% Uptime Benchmark for Enterprise AI Apps

A 99.99% availability target allows approximately:
- 4.32 minutes of downtime in a 30-day period
- 52.56 minutes of downtime per year
That target applies to the complete user-facing service, not merely the web server.
A meaningful availability calculation should ask whether an eligible AI request received a valid response within the agreed service threshold.
A basic formula is:
Availability = successful eligible requests ÷ total eligible requests × 100
However, the team must define “successful” precisely.
Does a response count as successful when it arrives after 40 seconds? Does a fallback response count if it violates the required JSON structure? Does a partial stream count? Should scheduled maintenance be excluded? Are provider-policy refusals failures or expected outcomes?
The service-level definition must answer these questions before the percentage has business meaning.
Evidence Required to Publish an Achieved 99.99% Result
A defensible case study should include:
- Measurement period
- Total eligible requests
- Successful request count
- Failed request count
- Latency threshold
- Excluded events
- Provider distribution
- Number of fallback events
- Recovery time
- Monitoring source
- Incident-report methodology
Without these records, 99.99% should be described as an engineering target, not a verified outcome.
Read More: Why Basic ChatGPT Clones Will Go Bankrupt in 2026
The Operational Dashboard Behind the Architecture
Multi-model resilience requires administrative visibility.
A useful AI operations dashboard should show:
- Current provider health
- Model-level success rates
- Latency percentiles
- Rate-limit events
- Request volume
- Token use
- Provider cost
- Fallback volume
- Circuit-breaker state
- Quality-evaluation alerts
- Manual route controls
- Error trends
- User-plan consumption
The operator should also be able to disable a model, change routing weights, adjust thresholds, and review fallback logs without requiring a code deployment for every operational change.
This admin layer converts multi-model integration from a developer feature into a manageable business capability.
What We Tested Before Enabling Automatic Failover
Automatic routing should not be activated after a single successful API test.
The validation process should include:
Provider Failure Tests
The team deliberately simulates timeouts, rate limits, server errors, malformed responses, interrupted streams, and unavailable models.
Context-Continuity Tests
Multi-turn conversations are switched between providers to verify that instructions, user preferences, and relevant history remain intact.
Structured-Output Tests
Requests requiring JSON, tool calls, or predefined schemas are tested on every approved fallback route.
Load and Concurrency Tests
The router is tested under concurrent traffic to ensure that failover does not overload the secondary provider.
Cost Tests
The platform measures whether fallback traffic materially changes cost per request, token consumption, or gross margin.
Safety Tests
Fallback providers are evaluated against the same application policies. A model switch must not weaken moderation, permissions, or data-handling controls.
Recovery Tests
Once the primary provider becomes healthy, traffic is restored gradually rather than moved back immediately after a single successful request.
Founder Decision Signals
Founder Decision Signals
Dependency Risk
If one external API controls the product’s core function, provider disruption becomes direct customer-facing downtime.
Quality Consistency
Fallback models should be approved through task-specific evaluations rather than assumed to be interchangeable.
Margin Control
Routing policies must consider token cost and subscription economics alongside availability.
Enterprise Readiness
Buyers should ask for observability, access control, audit logs, data-boundary rules, and documented recovery procedures.
Common Multi-Model Architecture Mistakes
Adding a Second Provider Without an Orchestration Layer
Two API integrations do not create automatic resilience. The application still needs health detection, routing decisions, request translation, and state management.
Failing Over on Every Error
Authentication failures, invalid requests, safety refusals, and configuration errors should not all trigger another provider. Each failure class needs an explicit policy.
Ignoring Semantic Differences
A technically successful fallback may still produce an unacceptable answer. Quality evaluations must test realistic user tasks.
Sending Sensitive Data to an Unapproved Route
Fallback logic must respect data-residency, privacy, contractual, and compliance requirements. Final compliance depends on jurisdiction, legal review, integrations, deployment choices, and the operating model.
Hiding Failures Without Investigating Them
Fallback reduces customer impact, but it should not hide chronic provider errors from the engineering team. Every reroute needs monitoring and review.
Claiming Uptime Without Defining the Measurement
An uptime percentage without a measurement period, success definition, and monitoring source is a marketing statement rather than an engineering result.
Why This Architecture Matters Commercially
Backend resilience influences more than infrastructure performance.
It affects:
- Customer trust
- Subscription retention
- Enterprise procurement
- Support volume
- Service-level commitments
- Gross margin
- Product reputation
- Expansion into critical workflows
- Dependence on one vendor
- Negotiating leverage with providers
A startup may initially tolerate occasional errors. An enterprise buyer using the app for support, document analysis, internal search, or workflow automation will expect a documented reliability strategy.
That makes the routing layer part of the product’s commercial value.
Miracuves’ White-Label AI App Approach
Miracuves helps founders build white-label AI applications with branded interfaces, source-code ownership, admin controls, monetization workflows, and configurable model integrations.
For multi-model products, the platform architecture can include a provider-neutral orchestration layer rather than tying the entire product to a single AI vendor. This creates a stronger foundation for routing controls, future model additions, cost optimization, and service continuity.
Miracuves’ existing ChatGPT clone solution supports branded AI product development, while its multi-model Poe-style platform guide provides additional context on model switching, usage analytics, routing controls, and scalable AI orchestration.
Final Thoughts: The Best AI App Is Built for Failure
The best AI application is not the one with the most convincing demonstration.
It is the one that continues operating when a dependency slows down, a quota is exhausted, or a provider returns an unexpected error.
Multi-model fallback architecture reduces single-provider risk by separating the product from the model endpoint. Yet resilience does not come from connecting several APIs alone. With Miracuves Solutions, it comes from disciplined routing policies, normalized context, compatibility testing, monitoring, recovery controls, security boundaries, and measurable service objectives.
For AI founders, CTOs, and enterprise buyers, the right evaluation question is no longer, “Which model does the app use?”
It is, “What happens when that model is unavailable?” Let’s Build Together
FAQs
What is a multi-model AI fallback system?
A multi-model fallback system routes an AI request to another approved model or provider when the primary route fails to meet defined availability, latency, or capacity conditions.
Can an AI app automatically switch from OpenAI to Claude?
Yes, provided the application has a provider-neutral orchestration layer, compatible request adapters, centralized policy controls, and an approved fallback rule. Directly replacing one endpoint with another is usually insufficient for complex conversations or tool-based workflows.
Does multi-model routing guarantee zero downtime?
No. It reduces the risk that one provider failure will stop the entire application. The app can still be affected by its own infrastructure, networking, databases, authentication, shared cloud dependencies, or failures affecting multiple providers.
What errors should trigger an AI model fallback?
Typical candidates include eligible rate-limit responses, timeouts, temporary server errors, and sustained latency beyond an approved threshold. Authentication errors, malformed requests, and safety refusals should normally follow separate policies.
How is AI app uptime calculated?
A practical method divides successful eligible requests by total eligible requests during a defined measurement period. The team must also define latency limits, exclusions, partial responses, and what qualifies as a valid result.
How much downtime does 99.99% uptime allow?
It allows approximately 4.32 minutes in a 30-day period or 52.56 minutes per year.
Can fallback routing change the quality of the response?
Yes. Models differ in tone, reasoning, structured output, tool use, safety behaviour, context capacity, and cost. Each fallback route should pass task-specific quality tests.
Is a multi-model AI app more expensive?
It can introduce additional engineering, monitoring, and testing costs. Some routing techniques, such as hedged requests, may also increase inference spend. However, intelligent routing can balance availability, model quality, latency, and cost more effectively than a single fixed route.