Key Takeaways
- Commercial AI APIs are simple to launch but can create rapidly increasing variable costs as usage grows.
- A self-hosted LLM replaces per-token billing with infrastructure, deployment, and capacity-management costs.
- Under the modeled high-volume workload, monthly query-processing costs fell from $52,500 to about $7,946.
- That represents an estimated 84.9% cost reduction for suitable high-volume AI workloads.
- A hybrid architecture can preserve premium API access while routing predictable tasks to privately hosted models.
Cost Signals
- Operators should compare token volume, prompt size, output length, concurrency, and peak demand before choosing infrastructure.
- Self-hosting requires GPU capacity, model serving, monitoring, scaling, security, and engineering support.
- Commercial APIs remain useful for low-volume workloads, premium reasoning, rapid testing, and unpredictable demand.
- Caching, request batching, model quantization, and intelligent routing can improve self-hosted inference economics.
- Admin dashboards should track model usage, latency, failures, infrastructure utilization, and cost per completed task.
Real Insights
- The largest AI operating-cost risk often appears after product adoption accelerates, not during initial development.
- Self-hosting is not automatically cheaper when traffic is low, inconsistent, or technically difficult to predict.
- The right comparison is cost per successful business task, not only the price of individual input and output tokens.
- Owning suitable inference infrastructure can improve gross margins, pricing flexibility, and provider independence.
- Miracuves builds ChatGPT-like apps with self-hosted LLM deployment, API routing, cost monitoring, and scalable AI backend workflows.
The most dangerous cost in an AI application is often not development.
It is success.
A ChatGPT-like app may launch with a manageable commercial API bill while serving only a few hundred users. Once adoption accelerates, however, the same pay-per-token model can turn every new conversation, generated document, support response, or automated workflow into a rapidly expanding variable expense.
That creates an uncomfortable operating equation:
More usage generates more revenue, but it also creates an almost perfectly correlated inference bill.
For SaaS CFOs, technology investors, and AI application operators, this is not merely a cloud-engineering concern. It directly affects gross margin, pricing flexibility, cash-flow planning, customer acquisition limits, and company valuation.
A self-hosted model can change that equation. Instead of purchasing every token from a third-party provider, the operator pays for provisioned inference capacity and distributes that cost across a high volume of requests.
Under the benchmark developed in this report, moving suitable workloads from a commercial API to a privately operated Llama-class model reduces modeled monthly query-processing expenditure from $52,500 to approximately $7,946.
That represents an 84.9% reduction, rounded to 85%.
Through its AI app development solutions, Miracuves helps businesses build scalable ChatGPT-like platforms with self-hosted models, intelligent model routing, commercial API fallbacks, private knowledge bases, infrastructure monitoring, and enterprise-level operational controls. The objective is not simply to replace commercial APIs, but to design a hybrid AI architecture that protects performance, quality, and margins as usage grows.
Read More: What is ChatGPT App and How Does It Work?
The Token Tax: How API Bills Destroy AI Startup Margins
Commercial APIs are attractive because they remove a large amount of early infrastructure work. A product team can integrate a capable model, test demand, and launch without operating GPU clusters or maintaining an inference stack.
That convenience is strategically valuable during validation.
The problem appears when an API-dependent application begins to scale. Its inference cost remains attached to every unit of consumption. The operator does not gain the same fixed-cost leverage that traditional SaaS products often achieve as more customers share the same infrastructure.
Consider an AI support platform that charges a customer $99 per month. Its margin may look healthy when each account generates a few hundred short requests. If usage rises sharply, long prompts, retrieved context, conversation history, retries, tool outputs, and generated responses can consume a large part of that subscription revenue.
The operator then faces four poor choices:
- Increase prices and weaken competitiveness.
- Introduce usage caps and reduce customer value.
- Absorb the token bill and accept lower margins.
- Redesign the inference architecture after costs have already escalated.
The more strategic decision is to measure cost per completed task before growth makes the architecture difficult to change.
Read More: Top ChatGPT Features Every Startup Should Know
Benchmark Methodology: What the 85% Figure Actually Measures
This benchmark models a high-volume AI application handling repeatable tasks such as:
- Support-response drafting
- Document classification
- Information extraction
- Product-description generation
- Internal knowledge retrieval
- Structured summarisation
- Workflow triage
- First-pass content moderation
These workloads are better candidates for a smaller self-hosted model than advanced scientific reasoning, complex coding, multimodal analysis, or high-stakes decision support.
Meta originally released Llama 3 in 8-billion and 70-billion-parameter variants and positioned the family for instruction following, reasoning, coding, and other common language tasks. Meta subsequently expanded the family through Llama 3.1, including longer-context and larger variants.
Benchmark workload
| Variable | Assumption |
|---|---|
| Monthly queries | 50,000,000 |
| Average input tokens per query | 500 |
| Average output tokens per query | 150 |
| Total tokens per query | 650 |
| Monthly input tokens | 25,000,000,000 |
| Monthly output tokens | 7,500,000,000 |
| Total monthly tokens | 32,500,000,000 |
| Candidate private model | Quantised Llama 3.1 8B-class model |
| Private infrastructure | 11 NVIDIA L4 GPU nodes |
| Monthly operating period | 730 hours |
| Infrastructure contingency | 40% above raw compute |
The 40% allowance is designed to represent costs that simplistic comparisons often omit:
- CPU and memory overhead
- Storage
- Load balancing
- Logging and monitoring
- Orchestration
- Redundant capacity
- Engineering support
- Deployment maintenance
It is still a planning assumption. A production total-cost model should replace it with the organisation’s measured staffing, networking, observability, failover, and support expenses.
Read More: How to Build an App Like ChatGPT: Developer Guide
The Mathematics Behind the 85% Cost Reduction
For the commercial API side, the model uses the published standard pricing of a current mini-tier OpenAI model:
- Input: $0.75 per million tokens
- Output: $4.50 per million tokens
OpenAI’s pricing page also lists separate cached-input pricing and batch-processing options. Those discounts are not applied here because this benchmark models standard interactive processing without assuming that every request can be cached or delayed.
Step 1: Calculate commercial API input cost
Monthly input tokens:
50,000,000 queries × 500 input tokens = 25,000,000,000 input tokens
Convert that to million-token billing units:
25,000,000,000 ÷ 1,000,000 = 25,000 units
Input cost:
25,000 × $0.75 = $18,750
Step 2: Calculate commercial API output cost
Monthly output tokens:
50,000,000 queries × 150 output tokens = 7,500,000,000 output tokens
Convert that to million-token billing units:
7,500,000,000 ÷ 1,000,000 = 7,500 units
Output cost:
7,500 × $4.50 = $33,750
Step 3: Calculate total commercial API cost
$18,750 + $33,750 = $52,500 per month
The commercial API cost per query is therefore:
$52,500 ÷ 50,000,000 = $0.00105 per query
That looks small in isolation. At 50 million monthly requests, it becomes a material operating expense.
Read More: How AI Chat Platforms Make Money
Benchmarking Llama 3 on a Private GPU Cluster
For the self-hosted side, the benchmark uses Google Cloud’s publicly listed price for a g2-standard-4 accelerator-optimised virtual machine with one NVIDIA L4 GPU:
$0.706832276 per hour
Pricing varies by region, contract, reservation structure, and cloud configuration. This figure is a public list-price input rather than a negotiated Miracuves rate.
Step 1: Calculate raw GPU cluster cost
For 11 nodes running across a 730-hour month:
11 × $0.706832276 × 730 = $5,675.87
Step 2: Add the operating-cost allowance
Applying the 40% allowance:
$5,675.87 × 1.40 = $7,946.22
Step 3: Calculate self-hosted cost per query
$7,946.22 ÷ 50,000,000 = $0.0001589 per query
Rounded:
$0.000159 per query
Step 4: Calculate the reduction
Monthly saving:
$52,500 − $7,946.22 = $44,553.78
Percentage reduction:
$44,553.78 ÷ $52,500 × 100 = 84.86%
Rounded:
84.9%, or approximately 85%
Modeled Monthly Inference Cost Comparison
| Cost Measure | Commercial API | Self-Hosted Cluster |
|---|---|---|
| Monthly queries | 50 million | 50 million |
| Monthly tokens | 32.5 billion | 32.5 billion |
| Raw processing cost | $52,500 | $5,675.87 |
| Infrastructure and operating allowance | Included in API rate | $2,270.35 |
| Total modeled monthly cost | $52,500 | $7,946.22 |
| Cost per query | $0.00105 | $0.000159 |
| Modeled reduction | Baseline | 84.9% |
Read More: How Safe is a White-Label ChatGPT App? Security Guide 2026
Is the Cluster Large Enough?
Cost mathematics alone does not prove production capacity.
The system must also sustain the required output rate, acceptable time to first token, concurrency, context length, uptime, and response quality.
The benchmark generates 7.5 billion output tokens per month. Spread evenly across a 30-day month, that is approximately:
7,500,000,000 ÷ 2,592,000 seconds = 2,894 output tokens per second across the cluster
Across 11 GPUs:
2,894 ÷ 11 = approximately 263 output tokens per second per GPU
That is the required average throughput, not a guaranteed L4 performance claim.
Before approving the architecture, the operator must run the intended model, quantisation format, inference server, prompt lengths, batch sizes, and concurrency pattern on the selected hardware. NVIDIA notes that production inference economics should be evaluated using measures such as throughput, tokens per watt, tokens per second per user, and cost per million tokens—not raw model speed alone.
A benchmark is therefore incomplete until it tests:
- Sustained tokens per second
- Peak concurrency
- P50, P95, and P99 latency
- Time to first token
- Maximum context length
- GPU memory consumption
- Batch efficiency
- Queue depth
- Error and retry rates
- Output acceptance rate
Read More: Best ChatGPT Clone Script in 2026: Features & Pricing Compared
Why Self-Hosting Does Not Win at Every Volume
The 85% result should not be interpreted as “self-hosted models are always cheaper.”
A commercial API can still be the stronger financial choice when:
- Traffic is low or unpredictable.
- The GPU cluster would remain idle.
- The application requires frontier-level reasoning.
- The team lacks machine-learning operations expertise.
- The product needs immediate access to new model capabilities.
- Traffic has extreme peaks but a low monthly average.
- The workload cannot tolerate quality differences.
- The business cannot justify redundancy and on-call operations.
The most expensive GPU is often not the one with the highest hourly price. It is the one that is provisioned but underused.
Commercial API providers aggregate demand across many customers. A small application benefits from that shared infrastructure without owning idle capacity.
Self-hosting becomes more attractive when traffic is sufficiently large, predictable, and batchable—or when control, privacy, customisation, and data-residency requirements justify the additional operational layer.
Read More: Business Model of ChatGPT 2026: Features, Revenue, and Strategy
The Break-Even Point Is a Moving Target

At the benchmarked token profile, the commercial API cost is approximately $0.00105 per request.
Using the modeled private-cluster expenditure of $7,946.22, a simple static break-even calculation is:
$7,946.22 ÷ $0.00105 = approximately 7.57 million queries per month
However, that number should not be used mechanically.
An 11-GPU cluster would likely be oversized for a workload of only 7.57 million short requests. A production design would scale the cluster, purchase commitments, or use autoscaling according to measured demand.
The real break-even formula is:
Self-hosted monthly cost ÷ commercial cost per successful request
But “successful request” matters. A cheaper model that produces an unusable answer, triggers retries, or increases human review may cost more at the business level.
Cost Per Successful Task Is More Important Than Cost Per Token

Suppose a self-hosted model costs $0.000159 per request but only 80% of outputs pass the application’s quality gate.
The cost per accepted output becomes:
$0.000159 ÷ 0.80 = $0.000199
That is still materially below the commercial benchmark, but the gap is smaller.
Now add:
- Retry tokens
- Human escalation
- Failed tool calls
- Longer prompts required to compensate for model limitations
- Larger retrieval contexts
- Safety-review overhead
The correct unit is therefore not always cost per token. Depending on the product, the finance team may need to track:
- Cost per resolved support ticket
- Cost per approved document
- Cost per completed workflow
- Cost per accepted summary
- Cost per active user
- Cost per revenue-generating action
Read More: Why Basic ChatGPT Clones Will Go Bankrupt in 2026
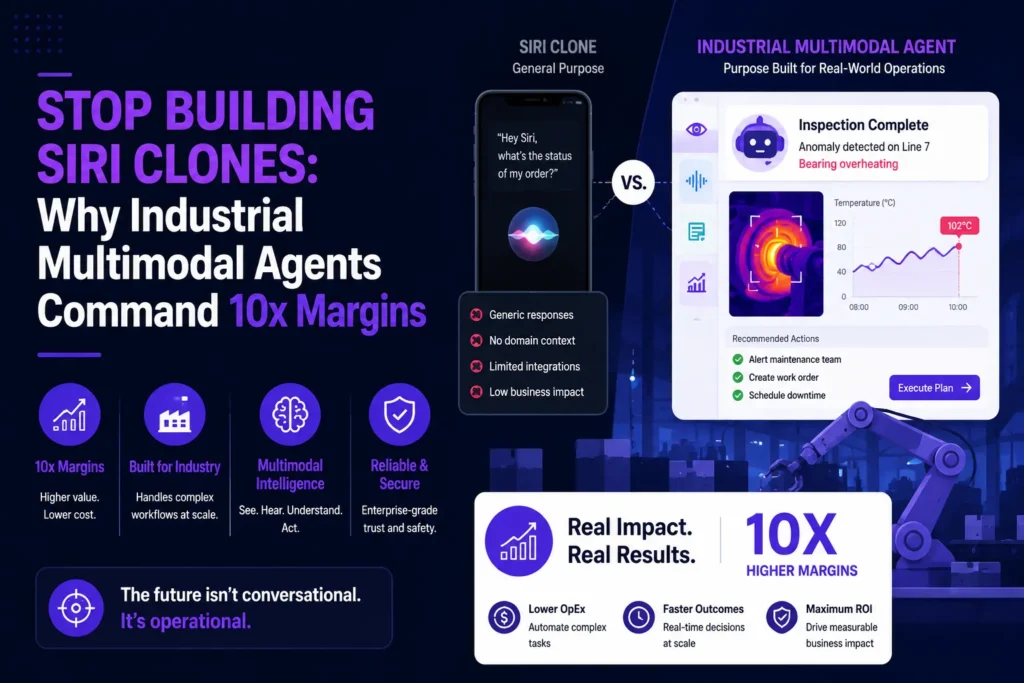
The Hybrid Architecture That Protects Cost and Quality

The strongest production strategy is often not a total replacement of commercial APIs.
It is selective model routing.
A routing layer can send high-volume, predictable tasks to a private model while escalating difficult requests to a premium commercial endpoint.
Suitable for a self-hosted model
- Classification
- Extraction
- Basic rewriting
- Standard summarisation
- FAQ answers grounded in approved data
- Tagging and categorisation
- Routine workflow decisions
- First-pass moderation
- Template-guided generation
Suitable for a commercial frontier model
- Complex reasoning
- Advanced coding
- Long-horizon agents
- Difficult multimodal interpretation
- High-stakes customer outputs
- Low-confidence private-model responses
- Rare requests requiring maximum model capability
A hybrid architecture creates three financial advantages.
First, it reduces the percentage of traffic billed at premium token rates.
Second, it prevents a smaller private model from being forced into tasks it cannot perform reliably.
Third, it gives the operator negotiating leverage and reduces dependence on a single inference provider.
Commercial platforms can also impose spend and request limits at account or organisational levels. A private or hybrid architecture gives the operator another capacity path when external rate limits or service policies become operational constraints.
Founder Decision Signals
Volume
Self-hosting becomes more attractive when monthly demand is high enough to keep GPU capacity productively utilised.
Predictability
Stable traffic is easier to provision economically than highly irregular demand with short, extreme peaks.
Task Complexity
Routine language tasks are stronger migration candidates than advanced reasoning or high-stakes outputs.
Operational Readiness
The team needs monitoring, model evaluation, rollback, security, scaling, and incident-response capabilities.
The 85% Margin Win: Why AI Operators Need Infrastructure Control
At the modeled scale, the annual difference is substantial.
Commercial API expenditure:
$52,500 × 12 = $630,000 per year
Modeled private-cluster expenditure:
$7,946.22 × 12 = $95,354.64 per year
Modeled annual saving:
$630,000 − $95,354.64 = $534,645.36
That saving could support:
- Additional engineering capacity
- Customer acquisition
- Product development
- Model evaluation
- Reliability improvements
- Lower customer pricing
- Stronger contribution margins
- Longer cash runway
For an investor, the deeper value is not simply the lower bill. It is the transition from an uncontrolled variable expense toward a more manageable infrastructure cost curve.
That can make revenue growth more valuable because each additional suitable query consumes capacity already owned by the platform—up to the point where another GPU node is required.
Infrastructure Ownership Does Not Mean Physical Hardware Ownership
“Self-hosted” does not necessarily mean purchasing servers and installing them in an office.
A private inference environment may run on:
- Dedicated cloud GPU instances
- Reserved cloud capacity
- Kubernetes-based GPU clusters
- Colocation infrastructure
- On-premise servers
- A combination of cloud and owned hardware
The important distinction is operational control.
The application operator controls the model weights permitted by the relevant licence, inference runtime, deployment configuration, scaling policy, logging, routing, and data path.
Google Cloud positions L4-powered G2 virtual machines as a cost-efficient option for inference workloads, while its accelerator pricing provides hourly rates that can be incorporated into a transparent operating model.
Risks That Can Erase the Savings
Mistakes AI Operators Should Avoid
Comparing Models Without a Quality Gate
A smaller private model and a frontier commercial model may not deliver equivalent outputs. Test business-task acceptance, factuality, safety, latency, and escalation rates before comparing costs.
Ignoring Idle GPU Capacity
A permanently running cluster can become expensive when demand is low. Measure hourly utilisation and consider autoscaling, scheduling, or a hybrid overflow route.
Counting Compute but Excluding Operations
Storage, networking, monitoring, engineering, redundancy, incident response, upgrades, and security belong in the total-cost calculation.
Migrating Every Request to One Private Model
A single model rarely provides the optimal balance of cost, latency, and quality for every task. Use workload classification and confidence-based escalation.
Treating the 85% Figure as Guaranteed
The result depends on the disclosed token volume, pricing, cluster size, workload suitability, and operating assumptions. Different conditions will produce different savings.
Security and Governance Must Be Part of the Cost Model
A private model can improve control over the inference path, but it does not automatically make an application secure or compliant.
The platform still needs:
- Encrypted data transfer
- Encrypted storage
- Role-based access control
- Audit logs
- Secret management
- Permission-based dashboards
- Prompt and output logging policies
- Abuse monitoring
- Model-version controls
- Data-retention rules
- Secure API integration
- Incident-response procedures
For regulated or privacy-sensitive workloads, the architecture can be configured to support relevant compliance workflows. Final compliance depends on the jurisdiction, data categories, legal review, vendors, integrations, and operating model.
Read More: How can I market my ChatGPT clone app successfully?
How a Miracuves AI Backend Can Support the Transition
A cost-controlled AI backend requires more than placing a Llama model on a GPU.
The application needs an orchestration layer that can decide:
- Which model should receive each request
- Whether the prompt contains sensitive information
- Whether the task needs a frontier model
- Whether a cached answer is available
- Whether the private cluster has capacity
- Whether the output passes the quality threshold
- Whether the request should be retried or escalated
- How usage should be attributed to each customer
Miracuves can help founders design an AI application foundation that combines a branded user experience, administrative control, usage metering, model routing, private inference, commercial API fallback, and cost observability.
Businesses evaluating this model can also explore the Miracuves ChatGPT clone platform, the wider ready-made solution ecosystem, and the guide to developing an AI chatbot platform. These pages provide useful next steps for teams moving from an AI interface toward a more complete operating platform.
Final Thoughts: Own the Workloads That Define Your Margin
The strategic question is not whether open-weight models are universally better than commercial APIs.
They are not.
The better question is:
Which workloads are predictable, frequent, measurable, and simple enough to move onto infrastructure the business controls?
At low volume, a commercial API can provide exceptional economic and operational value. At high volume, however, the same per-token convenience can become a serious margin constraint.
In the benchmark presented here, 50 million monthly requests generate a modeled commercial API bill of $52,500. A private Llama-class deployment using 11 L4 nodes, including a 40% operating allowance, costs approximately $7,946.
That represents an 84.9% cost reduction.
The 85% margin opportunity does not come from installing an open model and hoping for the best. It comes from disciplined workload selection, high infrastructure utilization, continuous quality evaluation, intelligent model routing, and strong operational control.
For a scaling AI company, model intelligence matters. But the architecture determining where that intelligence runs may ultimately decide whether growth strengthens the business—or simply expands its token bill.
At Miracuves, we help businesses design scalable AI architectures that balance model quality, infrastructure ownership, performance, and long-term operating costs.
FAQs
Is self-hosting an LLM always cheaper than using a commercial API?
No. Self-hosting is generally more attractive when usage is high, predictable, and suitable for the selected model. Commercial APIs may remain more economical for low traffic, irregular demand, frontier reasoning, or teams without the operational capacity to maintain private inference infrastructure.
How was the 85% AI cost reduction calculated?
The benchmark compares $52,500 in monthly commercial API charges with $7,946.22 in modeled self-hosted infrastructure and operating costs. The difference is $44,553.78, equal to 84.86% of the API expenditure.
Does the benchmark prove that Llama 3.1 8B matches a commercial frontier model?
No. The calculation models cost for workloads that can pass a quality gate on the private model. It does not claim capability parity across every reasoning, coding, multimodal, or safety-sensitive task.
What workloads are strongest candidates for a self-hosted LLM?
Common candidates include classification, extraction, standard summarisation, tagging, grounded FAQ responses, routine rewriting, workflow triage, and other repetitive tasks that can be evaluated objectively.
What hidden costs should be included in self-hosted LLM pricing?
Include GPU compute, CPU, memory, storage, network traffic, orchestration, monitoring, redundancy, engineering time, security, model upgrades, incident response, and idle capacity.
What is hybrid LLM routing?
Hybrid routing sends each request to the most suitable model. Routine tasks may run on a private open-weight model, while complex or low-confidence requests are escalated to a commercial frontier API.
How should a CFO evaluate LLM infrastructure?
Track cost per successful business outcome, GPU utilisation, commercial API cost per request, private-model acceptance rate, retry cost, escalation rate, infrastructure uptime, and gross margin by customer or feature.
Can Miracuves build a self-hosted AI application?
Miracuves can help structure AI applications with private-model deployment options, commercial API integrations, routing logic, branded interfaces, administrative controls, and usage monitoring. The final infrastructure should be scoped around workload volume, model requirements, latency, security, and deployment preferences.